Clearing disk space on OS X
Over the weekend, I’ve been trying to clear some disk space on my Mac. I’ve been steadily accumulating lots of old and out-of-date files, and I just wanted a bit of a spring clean. Partly to get back that the disk space, partly so I didn’t have to worry about important information files that might be getting lost in the noise.
Over the course of a few hours, I was able to clean up over half a terabyte of old files. This wasn’t just trawling through the Finder by hand – I had a couple of tools and apps to help me do this – and I thought it would be worth writing down what I used.
Backups: Time Machine, SuperDuper! and CrashPlan
Embarking on an exercise like this without good backups would be foolhardy: what if you get cold feet, or accidentally delete a critical file? Luckily, I already have three layers of backup:
- Time Machine backups to a local hard drive
- Overnight SuperDuper! clones to a local hard drive
- Backups to the CrashPlan cloud
The Time Machine backups go back to last October, the CrashPlan copies further still. I haven’t looked at the vast majority of what I deleted in months (some stuff years), so I don’t think I’ll miss it – but if I change my mind, I’ve got a way out.
For finding the big folders: DaisyDisk
DaisyDisk can analyse a drive or directory, and it presents you with a pie chart like diagram showing which folders are taking up the most space. You can drill down into the pie segments to see the contents of each folder. For example, this shows the contents of my home directory:
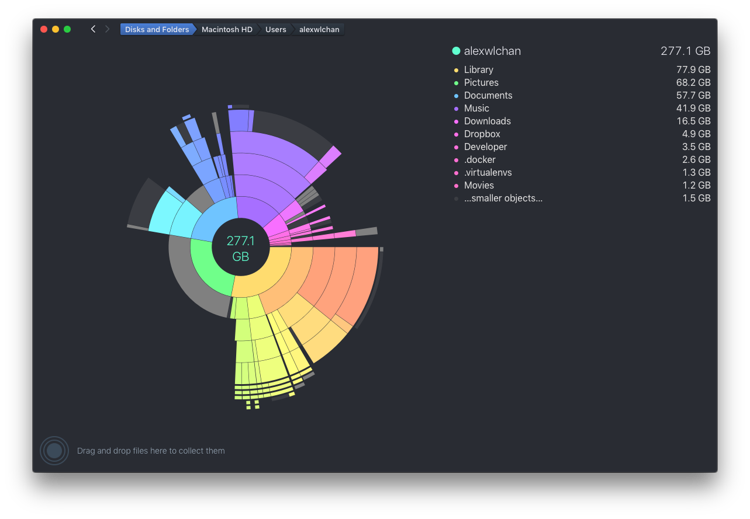
This is really helpful for making big space savings – it’s easy to see which folders have become bloated, and target my cleaning accordingly. If you want quick gains, this is a great app.
It’s also fast: scanning my entire 1TB boot drive took less than ten seconds.
For finding duplicate files: Gemini
Once I’ve found a large directory, I need to decide what (if anything) I want to delete. Sometimes I can look for big files that I know I don’t want any more, and move them straight to the Trash. But the biggest waste of space on my computer is multiple copies of the same file. Whenever I reorganise my hard drive, files get copied around, and I don’t always clean them up.
Gemini is a tool that can find duplicate files or folders within a given set of directories. For example, running it over a selection of my virtualenvs:
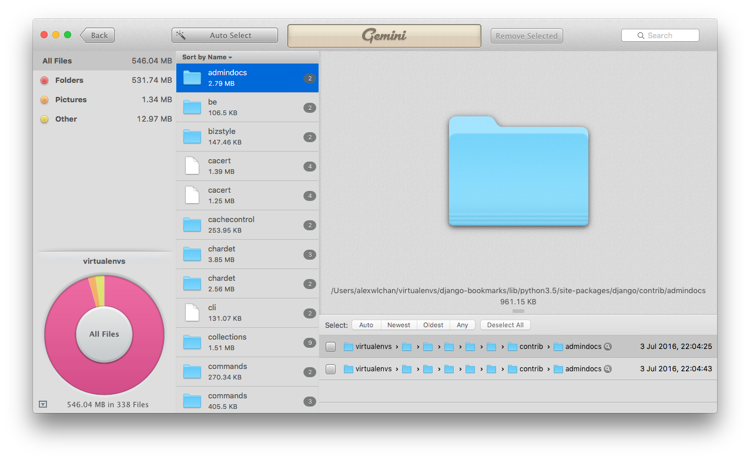
Once it’s found the duplicates, you can send files straight to the Trash from within the app. It has some handy filters for choosing which dupes to drop – oldest, newest, from within a specific directory – so doing so is pretty quick.
This is another fast way to reclaim space: deleting dupes saves space, but doesn’t lose any information.
Gemini isn’t perfect: it gets slow when scanning large directories (100k+ files), and sometimes it would miss duplicates. I often had to run it several times before it had found out all of the dupes in a directory. Note that I’m only running v1: these problems may be fixed in the new version.
File-by-file comparisons: Python’s filecmp module
Sometimes I wanted to compare a couple of individual files, not an entire directory. For this, I turned to Python’s filecmp module. This module contains a number of functions for comparing files and directories. This let me write a shell function for doing the comparisons on the command-line (this is the fish shell):
function filecmp
python -c "import filecmp; print(filecmp.cmp('''$argv[1]''', '''$argv[2]'''))"
endFish drops in the two arguments to the function as $argv[1] and $argv[2]. The -c flag tells Python to run a command passed in as a string, and then it’s printing the result of calling filecmp.cmp() with the two files – True if they match, False if they don’t.
I’m using triple-quoted strings in the Python, so that filenames containing quote characters don’t prematurely terminate the string. I could still be bitten by a filename that contains a triple quote, but that would be very unusual. And unlike Python, where quote characters are interchangeable, it’s important that I use double-quotes for the string in the shell: shells only expand variables inside double-quoted strings, not single-quoted strings.
Usage is as follows:
$ filecmp hello.txt hello.txt
True
$ filecmp hello.txt foo.txt
FalseI have this in my fish config file, so it’s available in any Terminal window. If you drag a file from the Finder to the Terminal, it auto-inserts the full path to that file, so it’s really easy to do comparisons – I type filecmp, and then drag in the two files I want to compare.
This is great if I only want to compare a few files at a time. I didn’t use it much on the big clean, but I’m sure it’ll be useful in the future.
Photos library: Duplicate Photos Cleaner
Part of this exercise was trying to consolidate my photo library. I’ve tried a lot of tools for organising my photos – iPhoto, Aperture, Lightroom, a folder hierarchy – and so photos are scattered across my disk. I’ve settled on using iCloud Photo Library for now, but I still had directories with photos that I hadn’t imported.
When I found a directory with new pictures, I just loaded everything into Photos. It was faster than cherry-picking the photos I already didn’t have, and ensures I didn’t miss anything – but of course, it also ensures that I import any duplicates.
Once I’d finished importing photos from the far corners of my disk, I was able to use this app to find duplicates in my photo library, and throw them away. It scans your entire Photo Library (it can do iPhoto and Photo Booth as well), and moves any duplicates to a dedicated album, for you to review/delete at will.
I chose the app by searching the Mac App Store; there are plenty of similar apps, and I don’t know how this one compares. I don’t have anything to particularly recommend it compared to other options, but it found legitimate duplicates, so it’s fine for my purposes.
Honourable mentions: find, du and df
There were a couple of other command-line utilities that I find useful.
If I wanted to find out which directories contain the most files – not necessarily the most space – I could use find. This isn’t about saving disk space, it’s about reducing the sheer number of unsorted files I keep. There were two commands I kept using:
Count all the files below the current directory: both files in this directory, and all of its subdirectories.
$ find . | wc -l 2443Find out which of the subdirectories of the current directory contain the most files.
for l in (ls); if [ -d $l ]; echo (find $l | wc -l)" $l"; end; end 627 _output 262 content 31 screenshots 3 talks 33 theme 11 util
These two commands let me focus on processing directories that had a lot of files. It’s nice to clear away a large chunk of these unsorted files, so that I don’t have to worry about what they might contain.
And when I’m using Linux, I can mimic the functions of DaisyDisk with df and du. The df (display free space) command lets you see how much space is free on each of my disk partitions:
$ df -h
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk2 1.0Ti 295Gi 741Gi 29% 77290842 194150688 28% /
devfs 206Ki 206Ki 0Bi 100% 714 0 100% /dev
map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
/dev/disk3s4 2.7Ti 955Gi 1.8Ti 35% 125215847 241015785 34%And du (display disk usage) lets me see what’s using up space in a single directory:
$ du -hs *
24K experiments
32K favicon-a.acorn
48K favicon.acorn
24K style
56K templates
40K touch-icon-a.acornI far prefer DaisyDisk when I’m on the Mac, but it’s nice to have these tools in my back pocket.
Closing thought
These days, disk space is cheap (and even large SSDs are fairly affordable). So I don’t need to do this: I wasn’t running out of space, and it would be easy to get more if I was. But it’s useful for clearing the noise, and finding old files that have been lost in the bowels of my hard drive.
I do a really big cleanup about once a year, and having these tools always makes me much faster. If you ever need to clear large amounts of disk space, I’d recommend any of them.