Reading web pages on my Kindle
Of everything I’ve tried, my favourite device for reading is still my e-ink Kindle. Long reading sessions are much more comfortable on a display that isn’t backlit.
It’s easy to get ebooks on my Kindle – I can buy them straight from Amazon. But what about content I read on the web? If I’ve got a long article on my Mac that I’d like to read on my Kindle instead, how do I push it from one to the other?
There’s a Send to Kindle Mac app available, but that can only send documents on disk. I tried it a few times – save web pages to a PDF or HTML file, then send them to my Kindle through the app – but it was awkward, and the quality of the finished files wasn’t always great. A lot of web pages have complex layouts, which didn’t look good on the Kindle screen.
But I knew the folks at Instapaper had recently opened an API allowing you to use the same parser as they use in Instapaper itself. You give it a web page, and it passes back a nice, cleaned-up version that only includes the article text. Perhaps I could do something useful with that?
I decided to write a Python script that would let me send articles to a Kindle – from any device.
Getting HTML from Instaparser
You can sign up for the free plan to get access to the service, and the limits are surprisingly generous – 1000 calls per month. That’s far more than I’ll read in the course of a month.
So suppose I have a web page. First I need to get some cleaned up HTML from the Instaparser API:
req = requests.get('https://www.instaparser.com/api/1/article',
params={'api_key': API_KEY, 'url': URL})
if req.status_code != requests.codes.ok:
raise RuntimeError("Unexpected error from the Instaparser API: %s" %
req.status_code)
This call is a fairly standard use of python-requests. Instaparser has a fairly simple API, which only requires two parameters: a URL, and an API key. You get an API key when you sign up for the service, and I have it included as a constant at the top of my script.
A successful API call returns a JSON dictionary with a couple of keys. The ones I’m interested in are title and html.
So I take the JSON I got from the request, and I save it to a file. Having it in a file will be useful later.
title = re.sub(u'[–—/:;,.]', '-', req.json()['title'])
tmpdir = tempfile.mkdtemp()
html_path = os.path.join(tmpdir, '%s.html' % title.replace('"', '\''))
text = req.json()['html'].encode('ascii', 'xmlcharrefreplace')
with open(html_path, 'wb') as outfile:
outfile.write(b"<html><body>%s</body></html>" % text)
I have to be a little careful here: there are some characters that aren’t allowed in filenames, so I throw them away before using the title as the name of the file. Then I create a temporary directory for storing the file with tempfile. (Because I use tempfile, I don’t bother cleaning up later: I trust the OS to do it for me. Arguably not good practice, but it’s never gone wrong so far.)
Then I save the HTML to the file. I’m using xmlcharrefreplace to turn any non-ASCII characters into their HTML entities. The Kindle and the Instaparser API use slightly different encodings, so if you send the HTML straight from the API, you see a bunch of weird characters. And I wrap it in <html> and <body> tags so that the Kindle parses it correctly as HTML. If you don’t include these, it just shows the raw HTML markup.
Getting the HTML to the Kindle
Amazon offer something called the Personal Documents Service, which is perfect for this use case:
You can send documents to your compatible devices by emailing the documents to your Send to Kindle email address. Your Send to Kindle email address is a unique address that is assigned to you when you register your compatible device.
Now we have the HTML in a file, we can just send it to this address.
I have an smtplib wrapper that makes it easy for me to send messages with attachments to a specified address from my Fastmail account. Using my wrapper, it looks something like this:
with FastMailSMTP(USERNAME, PASSWORD) as server:
server.send_message(from_addr="alex@alexwlchan.net",
to_addrs=[KINDLE_ADDR],
msg="",
subject="[autogen] Kindle email for %s" % url,
attachments=[html_path])
My email username and password, and my Send to Kindle address, are both defined as constants earlier in the file. I don’t include a body – I don’t think Amazon would do anything with it – and then I attach the file.
This sends it into the aether, and within a minute or so, a cleanly-formatted version of the article arrives on my Kindle.
If you don’t use Fastmail, you’ll need to provide another wrapper. If your email provider supports SMTP (which is most major providers, I think), you should be able to modify my Fastmail wrapper pretty easily – just swap out the SMTP server address and port on line 11. You can usually find these settings by Googling “<email provider> smtp settings”.
Automating the process
Now I have a script that can send web pages to my Kindle, but it would be annoying if I had to open it every time I wanted to use it. So I have it hooked into a couple of tools.
For my Mac, I have a small snippet of code at the end of the script that takes a single command-line argument, and sends that to my Kindle:
def main():
url = sys.argv[1]
html_path = get_html_from_url(url)
send_html_page_to_kindle(url, html_path)
To invoke this script, I have a Keyboard Maestro macro that gets the URL of the frontmost tab in Safari, and passes that to the script:
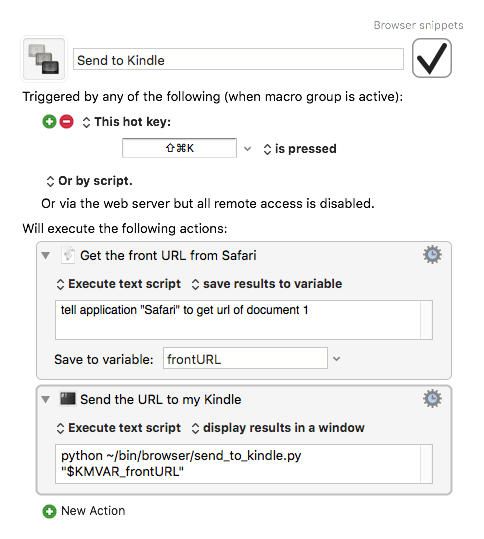
On my iPhone, the natural choice is Pythonista. It provides the appex module, which gives you input from the system share sheet. In particular, appex.get_url() lets me get a URL, so anywhere I can get the iOS share sheet, I can invoke the Pythonista action extension and run this script.
If you want, you can download a complete copy of the script. The same script runs on boht platforms. It requires a bit of configuration: you’ll need to set up your Instaparser API key, and configure an account for sending emails. And my SMTP wrapper requires Python 3.
It’s definitely not perfect. Occasionally the Instaparser API gets confused, and spits out garbage, or skips a large chunk of the page. But those instances are pretty rare.
There’s also no support for images. Any images in the original page just show a missing image icon on the Kindle. Fixing this requires a lot more work – rather than using HTML, you have to download all the images, bundle them into a MOBI file, rewrite bits of the text – and it’s more effort than it’s worth. Besides, the e-ink display is hardly optimised for viewing images.
But overall? This has been pretty nice. I don’t read everything on my Kindle, but whenever I see a long scroll bar, my hand reaches for that button. If you’ve got a Kindle, I’d recommend trying something like this.