Experiment: GitHub code search with de-duplication
When I’m trying to learn a new library or function, I often search for code that uses it on GitHub. Finding examples of other people’s usage helps me understand how to use it myself, especially if the docs are patchy or unhelpful.
But GitHub search often includes duplicate results – if the same file has been copied into ten different repos, that shows up as ten search results. If I’m trying to find distinct examples of how to use a particular function or API, that duplication isn’t very useful.
Plain Git has some neat mechanisms for de-duplication, and you can search code across public repositories with the GitHub API. I had a play yesterday, and I was able to come up with a search implementation that combines search results if they point to identical files:
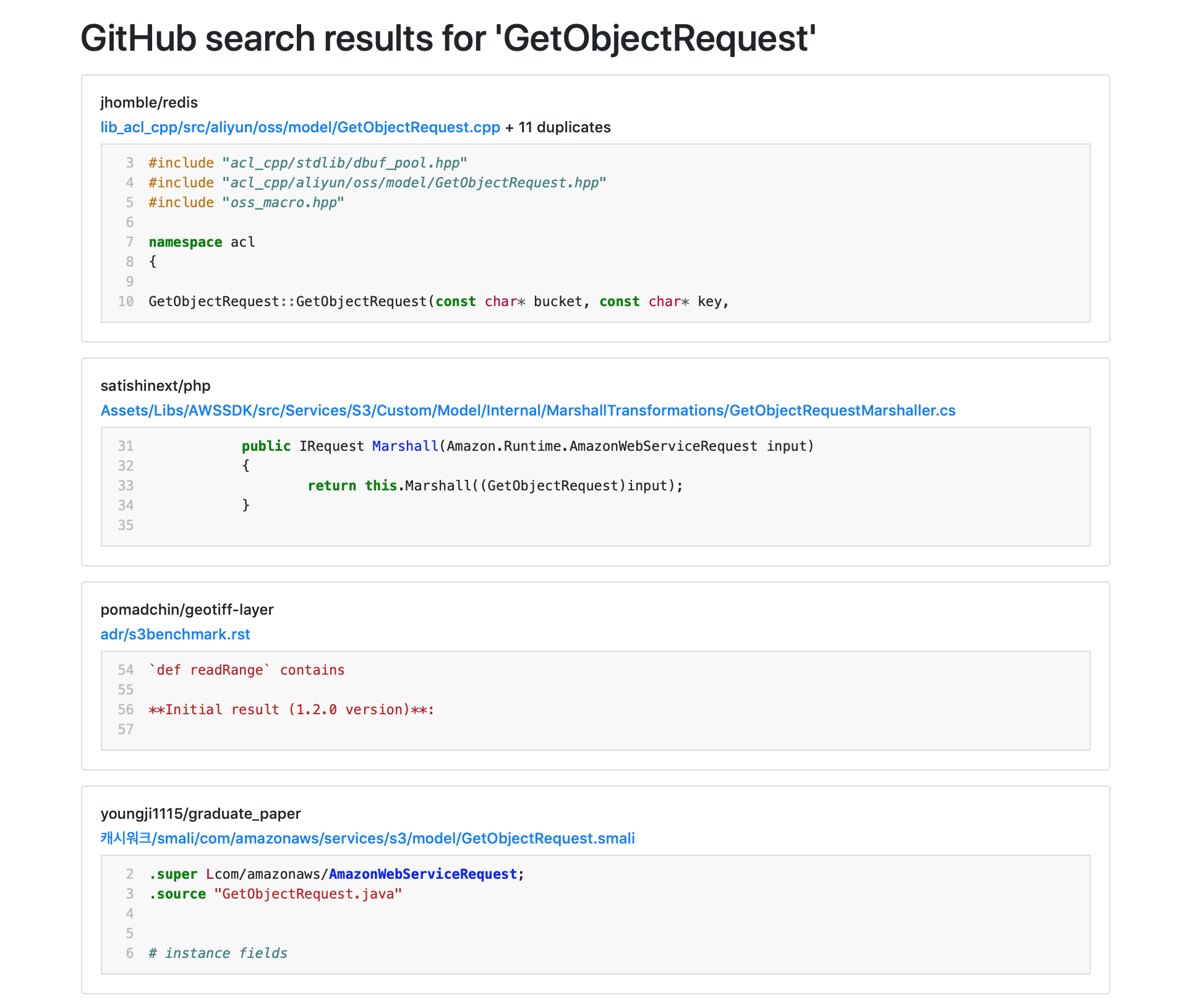
It starts by comparing SHA1 hashes of files – if two files have the same SHA1 hash, they’re the same – and it also looks for files that are similar but not identical. If two files have the same text, but different line endings, they’re treated as the same.
It’s an experiment, rather than a hardened search tool – it’s pretty slow, and it can only fetch a single page of results – but it proves the idea. You’d need a bunch of work to turn this into a production search implementation, and that’s the tricky bit. Nonetheless, I’m quite pleased with how well it works, given I spent just a few hours on it.
If you’re interested, all the code is on GitHub.