Digital preservation at Wellcome Collection
I wrote this article while I was working at Wellcome Collection. It was originally published on their Stacks blog under a CC BY 4.0 license, and is reposted here in accordance with that license.
This is the text version of a talk I gave at a GLAM Digital Champions event on 18th October 2019.
GLAM Digital Champions is a Cambridge-based community of practitioners for sharing ideas about the use of digital technologies in Gardens, Galleries, Libraries, Archives and Museums. It was set up by George Doji and Mary Chester-Kadwell. I met Mary at PyCon UK this year, and she invited me to come and give a brief overview of how we’re doing digital preservation at Wellcome.
You can also download my slides as a PDF.

Hello everyone, and thank you having me. It’s a pleasure to be here in Cambridge.
My name is Alex. I’m a senior software developer at Wellcome Collection in London, and today I’m going to give you a brief overview of how we do digital preservation at Wellcome Collection.
For those of you who don’t know us, Wellcome Collection is a free museum and library that aims to challenge how we all think and feel about health.
What does that actually mean?
Our building is a library, archive and museum all rolled into one. (No gardens yet, but we do have a couple of house plants!)
Wellcome Collection is a big place. We have a reference library and archive for researchers; we have a series of permanent and rotating exhibitions; we have event spaces and regular events; we write stories and we publish books. It covers a wide range of material around science, medicine, health and art. Alongside our physical archive, we have a large digital archive, and that’s what I’m going to talk about today.
We can imagine the process of digital preservation in three stages: production, storage, and retrieval. We choose what we’re going to save, we save it, we get it back later.
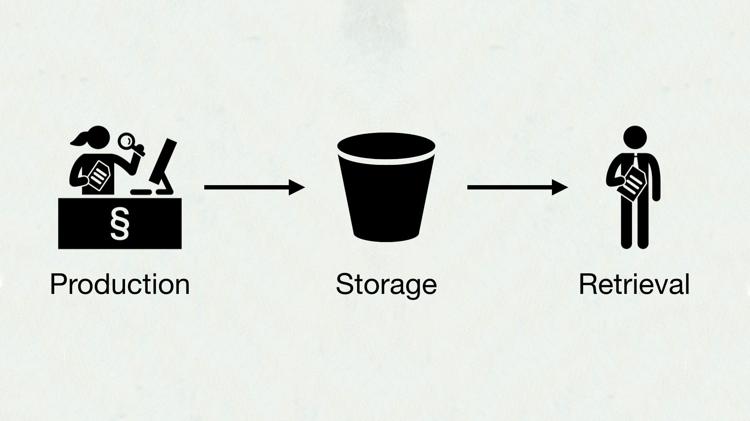
Let’s discuss those steps in turn.
Production
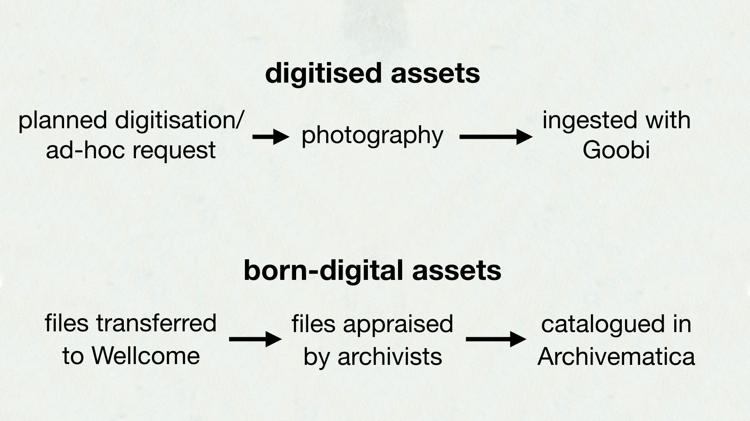
The production process varies at Wellcome, depending on whether we are considering digitised or born-digital files. Digitising means creating a digital representation of a physical object: for example, scanning a page or photographing a book. A born-digital file is one that started life as a digital file: maybe a Word document or a web page.
Let’s consider each in turn.
Digitisation
We have a lot of experience at Wellcome with digitisation: we’ve been digitising the collection for over a decade, and we have 40 million images.
How do we choose what to digitise? We have a long-term digitisation schedule, for parts of the collection we want to digitise — often planned years in advance. We also have capacity for ad-hoc digitisation. If a researcher in New Zealand wants to see something from our collections, they can ask for that to be digitised specially, and we can try to accommodate.
So we know what we want to digitise, and we’ve picked it off the shelf — how does the digitisation happen? There are a couple of streams:
- We have a contract with the Internet Archive, who scan our bound, printed books. They have specialist book scanners that mean they can scan very quickly.
- We send audiovisual material (VHS tapes, audio cassettes, etc.) to R3Store.
- TownsWeb work on-site at Euston Road and help to digitise our paper archives.
- We’re lucky to have a team of in-house photographers, who handle anything that needs extra care — maybe it’s fragile, bulky, or even radioactive. They work closely with the conservation team.
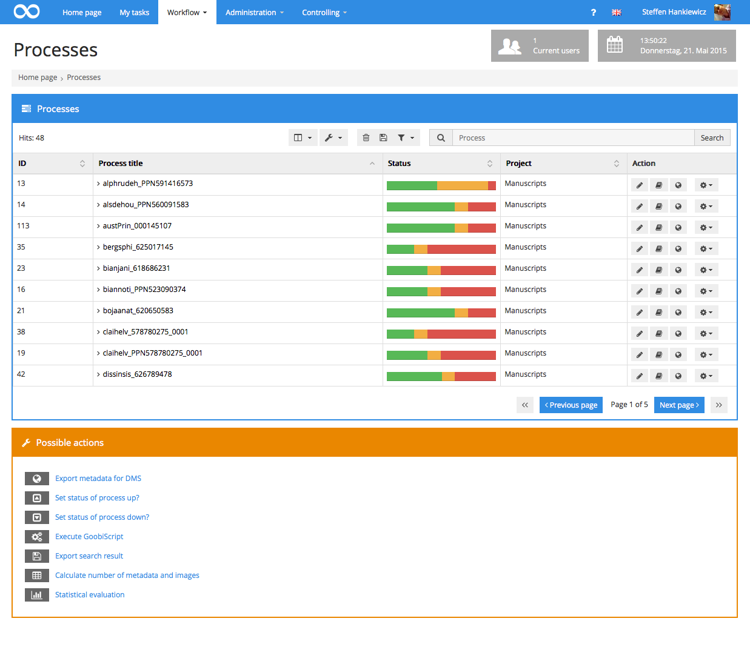
Now we have a pile of images, and we need to add them to the catalogue. We use a workflow manager called Goobi, made by Intranda. It collates metadata and OCR, adds checksums to the files, and spits out a bundle of images, METS (metadata) and ALTO (OCR data).
Born-digital
Born-digital archiving is something newer for us at Wellcome: it was the new shiny a few years ago, and we brought in lots of material. Now we’re starting to think more carefully about how we want to do born-digital archiving, how we’re going to catalogue it, and so on.
Suppose somebody offers us some files — we start by assessing them. Are these files a good fit for our collection? If they are, we’ll transfer them to Wellcome, and go through them in more detail. This is a more thorough analysis, where we’re looking for files that might need extra work before we can make it available. For example, PDFs of medical research are easier to present than something that’s password-protected.
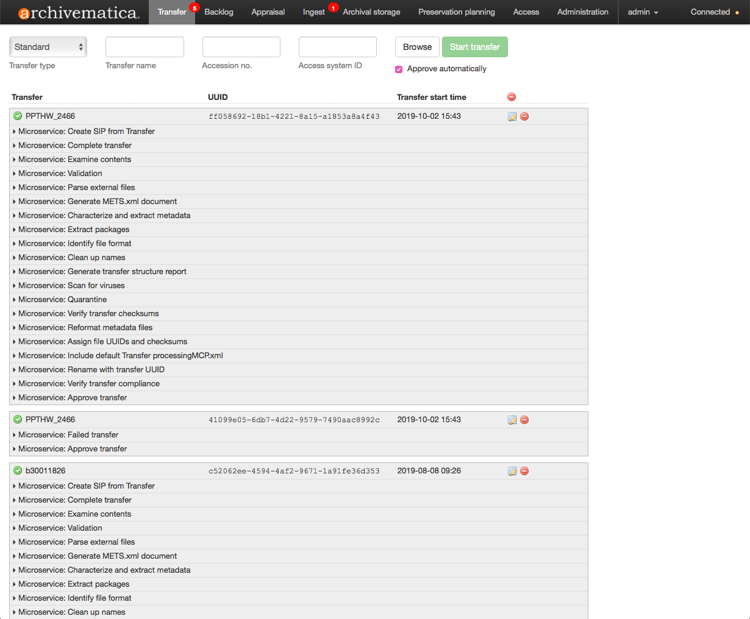
To prepare the files for ingest, we are about to start using Archivematica, an open-source digital preservation system made by Artefactual. It does a lot of automation for us: virus scanning, generating metadata and checksums, deleting .DS_Store and thumbs.db files that we don’t care about, and it spits out a bundle of files and metadata.
That gives you a brief overview of our production process, both digitised and born-digital.
At the end of this process, we have a clutch of files and metadata, but nowhere to put them. Where do keep these precious things? Let’s talk about storage.
Storage

Historically, we’ve used a storage system called Preservica, which is a fairly popular service used for digital preservation. (Although judging by hands in the room, it has yet to reach Cambridge!)
We’re in the process of migrating our storage away from Preservica. We wanted a storage service with the following attributes:
- Based on a common, open format for ingesting both digitised and born-digital assets
- A preference for open-source software
- That would allow us to batch process large volumes of data quickly. For example, if we wanted to re-run the OCR process for our digitised images.
- Human-readable storage layout. We want to make it as easy as possible for future developers to understand the storage, even if the current service is no longer in use.
- Running in the cloud, with content replicated to different locations and providers.
- Conforming to the DRY (Don’t repeat yourself) principles
And so we’re in the process of migrating our content from Preservica up to our new storage service. (As in, half an hour before the talk, I was in a café running migration scripts!)
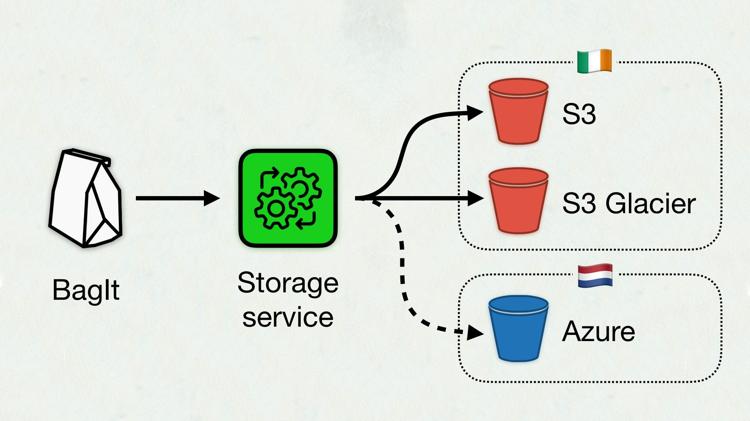
In our new storage service, you upload files in a BagIt package. This is a standard packaging format, used to pass around hierarchical filesystems. It’s often used in digital libraries, and both Goobi and Archivematica can produce BagIt packages.
The storage service unpacks the BagIt “bag”, counts out the files, verifies the checksums, and generally checks everything is in order. Assuming all is well, it uploads a copy of the bag to Amazon S3, and a second copy to S3 Glacier.
Later next year, we’ll be adding a replica to Azure Blob Storage in Amsterdam (both our S3 copies are in Dublin). This gives us an extra layer of redundancy and protection, in case AWS close our account or Dublin falls into the sea.
We know we’re lucky to have in-house software developers, so we want to share this work as much as possible. All the code for the storage service is open-source and MIT licensed, as is the original design document.
So we upload packages to the storage service, which keeps them safe in cloud storage for preservation evermore. Now suppose somebody comes to our website, and they want to see something we’ve preserved. How do they get it out? Let’s finish by discussing retrieval.
[Somebody asked about versioning in the Q&A — for example, what if we’ve digitised a book, and we need to replace one of the images?
The BagIt spec supports partial updates with “fetch files”. You build a package with a replacement image, and a fetch file that refers to files in another location — in our case, the location of previously stored bag.
The storage service tracks the versions of a given bag, keeps every version forever, and lets you see how a bag looked at a particular point in time.]
Retrieval
We have a number of services that sit in front of the storage service, and serve content to our website. Right now we only serve digitised content, but we want to think about how to do born-digital in the future.
DLCS (Digital Library Cloud Services) is a service that provides IIIF APIs for our digitised content. IIIF is a set of standards for presenting large images, commonly used in museums and libraries. DLCS presents three types of IIIF API for us:
- The IIIF Presentation API tells you what images are available in a particular work. If a book has 100 pages, and there are 100 digitised images, the Presentation API tells you how to find them.
- The IIIF Image API returns the images themselves. It can scale all the way from a tiny thumbnail (if you’re just skimming) to a deep zoomed version (if you’re studying in detail). This includes converting the image to different formats. Our original images are all JPEG2000, but we usually serve them as regular JPEG.
- The IIIF Auth API controls access to images. Most of our images are completely open access, but there are a handful where we need some access controls — for example if it’s an archive about somebody who’s still alive or recently deceased.

Loris is an open-source IIIF Image API server that we use to serve the other images on our website (a handful of catalogue images, and editorial images for events and exhibitions).
Presenting all the images on the site through IIIF gives them a consistent interface — the same code can be used to retrieve images everywhere.
(I previously wrote about our use of Loris in 2017.)
So that’s how we get the images —but what about the metadata that goes with them?

A lot of our metadata is split across different databases: Sierra for our library catalogue, Calm for our archives, Miro for our image collections, and so on. The same object is split across multiple places, and it’s hard for users to find it. It’s not clear which search box to use, and you only get a partial record.
We’ve been building a unified catalogue search that combines records from multiple databases, transforms them into a unified model, and presents all the data in one place. There’s also an open API that lets you get the search results as JSON, so other people can build their own tools on top of it.

What ties it all together is the new Wellcome Collection website, where people can browse the catalogue in a nice graphical viewer.
We’ve completely redesigned it, with new works pages for presenting this unified catalogue. It includes a IIIF viewer for doing deep zoom of images and browsing the pages of a book (pictured above). The new website is also much more accessible: it uses progressive enhancement and the OCR from our digitisation as alt text in the images.
Under the hood, it’s using the Catalogue API to get metadata, and DLCS and Loris to serve the images. We do a lot of user research on the website to get a sense of how well search is performing, how easily people are finding what they need, to track site performance, and so on.
So now we’ve gone from start to finish: we’ve chosen something we want to store, we’ve saved it in the storage service, and somebody has found it through our website on the other side. I hope this has given you a flavour of how we do digital preservation at Wellcome.
Read more
Browse the catalogue: wellcomecollection.org/works
Get our code: github.com/wellcometrust/platform
Browse our developer docs, learn how to use our APIs: developers.wellcomecollection.org/
Thanks to Christy Henshaw, Jonathan Tweed and Tom Scott for their help reviewing drafts of this talk.