Sans I/O programming: what, why and how (PyCon UK talk)
Last month I gave a talk about PyCon UK about “sans I/O programming”. This is a style of programming I’ve been trying to use for a while, and I’ve found it quite helpful. It’s not revolutionary, but it’s a nicer way to write code. The result is code that’s simpler, cleaner, easier to reuse and easier to test.
This isn’t an original idea or term: I first encountered it a couple of years ago while working on the hyper HTTP/2 library, and I’m sure the idea is older than that.
The talk was recorded, and you can watch it on YouTube:
You can read the slides and my notes on this page, or download the slides as a PDF.
The talk was transcribed, and these notes are based on that transcript. The two STTRs that day were Wendy Osmond and Hilary Maclean; I’m not sure who was transcribing my particular talk.
Links/recommended reading
Building Protocol Libraries the Right Way, Cory Benfield’s talk at PyCon 2016
Designing an async API, from sans-I/O on up, by Brett Cannon
SansIO – Migrating microservices to async, by João Alves
Slides and notes

I’m going to talk about sans I/O programming. This is a pattern of programming I’ve been trying to use the last couple of years. It helps my code be a bit simpler and cleaner to work with. It’s not revolutionary, it won’t change the way you code forever, but hopefully it will help you write slightly nicer code – whether or not you write Python for a day job.
I’ll show you what it means, some of the problems of not adopting this pattern and you might want to use it in your own codebase.

Hi, I’m Alex. If you want to live tweet along with this talk, I’m @alexwlchan.
I’ve been helping to organise PyCon UK for the last four years. [A common bit of feedback from 2018 was people asking for more technical talks – hence why I wrote this one!]
For my day job, I build digital preservation software for an organisation called the Wellcome Trust, who are sponsoring this year’s conference. I’ll talk more about my job in a moment.
I’m trans and I use they/them pronouns.

Photo credit: Wellcome Collection.
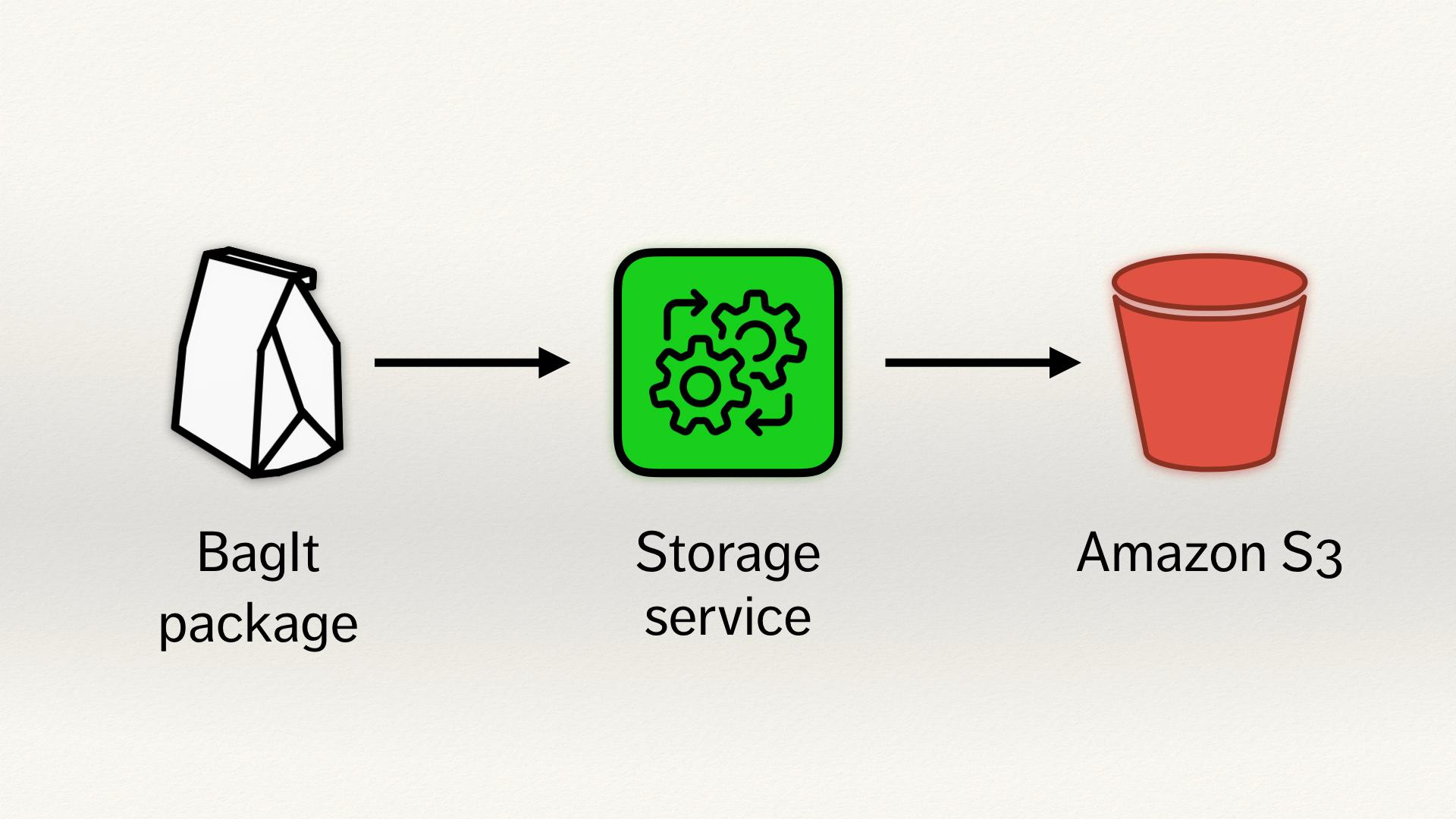
Icon credits: paper bag by Dorian Dawance, process/gears by Alice Design, bucket from AWS Simple Icons.
{kind=link}
We receive files in a BagIt package – BagIt is a format often used for digital archives, which might contain things like a digitised book, sound or video recordings, files we’ve received from somebody’s hard drive. They get uploaded to a storage service (which is the thing I build), we count out the files, verify checksums and so on, and assuming it’s all okay, we upload a copy to Amazon S3 where it will be stored in perpetuity.
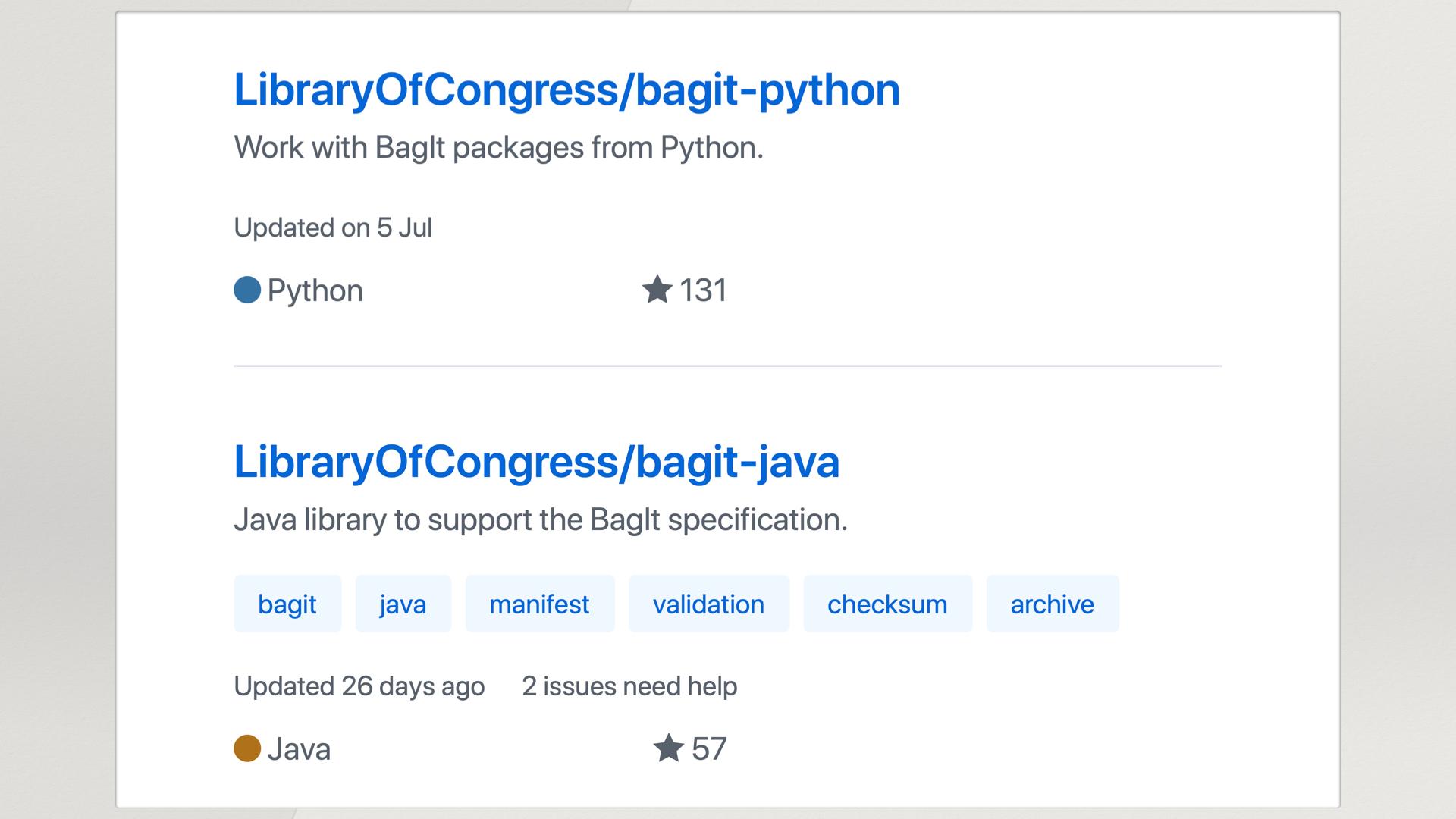
We looked on GitHub and we found two packages that will do this job for us. Brilliant! We’ll use these packages, install them in our project, and we’re good to go. We can use Python, or we could use Java (because we write in Scala at Wellcome), so we have choices – except we can’t.
Both of these libraries have a fairly fundamental design limitation. They assume that your BagIt packages exist as files on a local disk. They assume you’ve downloaded the whole bag, saved it somewhere, and now they’ll read it off your disk.

But our bags don’t exist on a disk – they exist in S3, and we don’t want to be downloading the whole bag every time we want to do some work. This means we can’t use these libraries.

That was a bit of a pain for us, but maybe this is just because BagIt is a weird, obscure packaging format, and the people who wrote it aren’t very good software developers? Nope.

There are more HTTP libraries than BagIt libraries. In the Python ecosystem we have a rich variety of them. There’s urllib3, aiohttp, Flask, there are command line tools like httpie, and yet if you ever try to look at some of these HTTP libraries you will discover you have the same problem we have with BagIt libraries. If a library doesn’t match your I/O model or async primitive, it can be really hard to use.
For example, if it’s a real pain to use Requests with Tornado unless you want to get really down and dirty with the Tornado threadpool. HTTP libraries end up being written to suit the I/O or the async primitive, and so they don’t share any code.
If you look at it, httplib does exactly what those BagIt libraries were doing, except with sockets instead of files. To handle a HTTP request, it reads data from a socket, does some parsing, reads some data from a socket, does some parsing, but if you’re not doing HTTP over a socket, or you want to control that socket yourself, that doesn’t work for you. Because the HTTP state machine logic in httplib is so closely tied to that logic, it’s really hard to disentangle the two.
Every time somebody wants to create a new HTTP library, they have to build their own interpretation of the parser and state machine. They’re getting no code reuse, and that’s kind of sad. We’re all told that code reuse is a good thing, we should strive to have more code reuse, so in something as fundamental as HTTP, maybe it’s an anti-pattern that we don’t seem to have as much code reuse as we would like.
I want to unpack the problems of not having so much code reuse. A couple of reasons.

We’re all solving the same problem, right? The idea of file formats or protocols is that we all have a very consistent understanding of what they mean. There is one way to parse a BagIt package. There is one way to make a HTTP request, and we should all agree what that format is. Creating another parser or another thing that’s going to repeat that logic isn’t really adding anything to the world; it’s just repeating code. That’s that time and effort that we could be spending on something better.

I imagine lots of people in this room think they can write an RFC compliant HTTP/1.1 or BagIt parser – I’m one of them – and we’re probably all wrong because parsing is really hard! So when we have multiple copies of the parser, and they’re all independent and not showing any code, that means they’re not sharing information about bugs. If I find a bug in gunicorn and fix it there, that same bug might exist in other HTTP stacks, but it’s unlikely it will get to them.


Put your hand up if you’ve ever opened a file in Python. (Pretty much every hand in the room goes up.) Keep your hand up if you can tell me every one of the 30 different flags that open() accepts, which operating systems they are available for and what they all do. (Every hand goes down.)
Fine, we don’t care about those because maybe our job is not to optimise I/O, but there are people whose job it is. It’s their job to squeeze an extra three socket calls or five file handles out of the system every second, and if it’s tied in with our parsing code, business logic, it’s harder to optimise our code.

I hope you all accept these are legitimate problems, and these are things we have to worry about. But it’s probably not a catastrophe. This is not a disaster. My computer is not going to crash tomorrow because I mixed my I/O and my business logic. That’s why this is often a thing that we don’t think about, because we can do our jobs without it. It slows us down, creates drag on development, adds some technical debt, but it’s not the end of the world. We can get by without it.

Never do I/O! We should rewrite everything as pure programming, give up on Python, just write Haskell, never do any side effects, never do any I/O.
That is not the message of this talk.

The better way is: never mix your I/O and business logic.
Try and keep those two things separate. You want to build a 50-foot wall in your programme, put business logic on one side, everything that’s doing in-memory operations, and put your I/O on the other side. Then define a clear interface between them. Push all the I/O out to the edges.
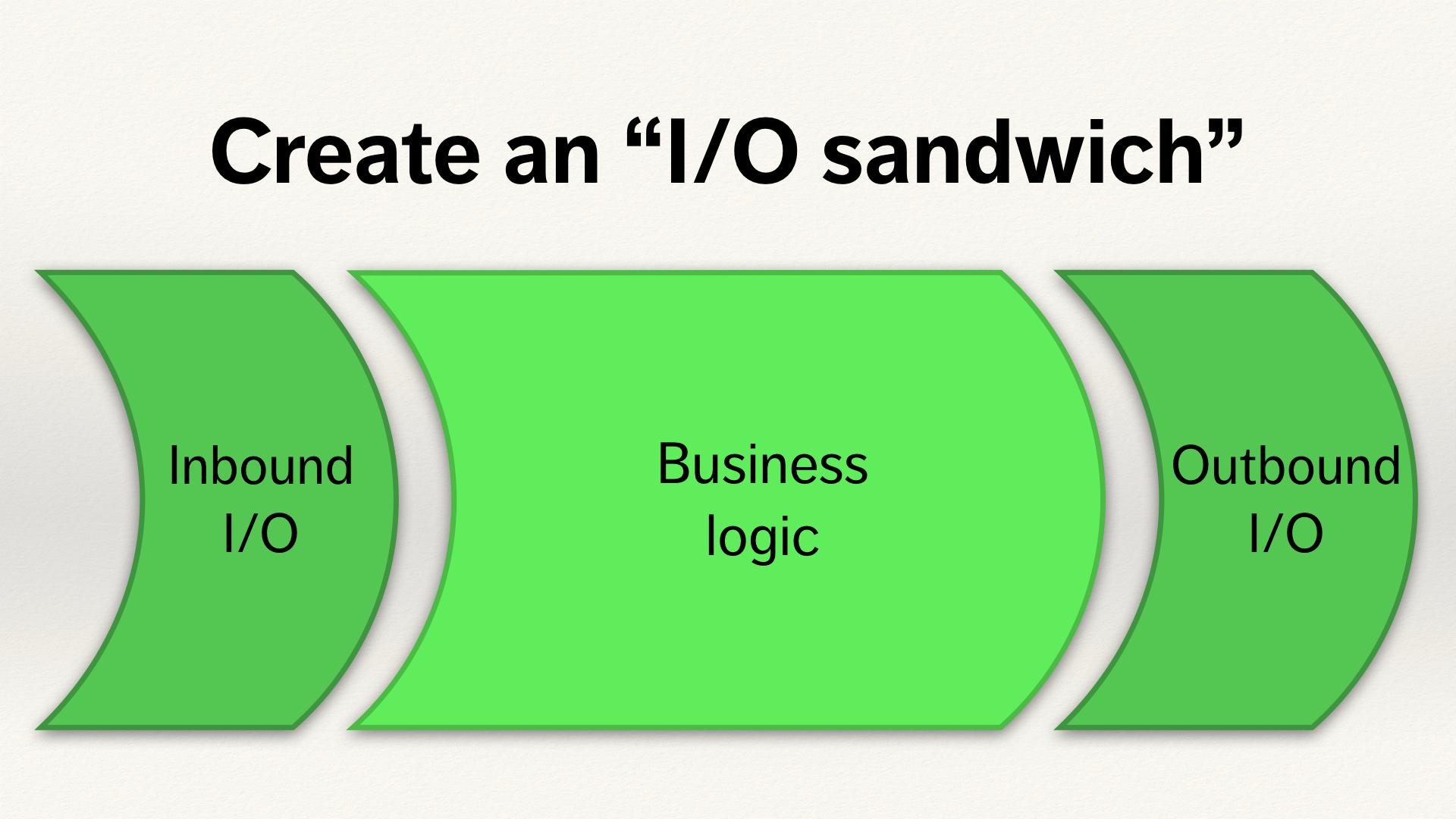




I/O introduces a huge number of failure cases to your programme, a whole new set of exceptions or error cases that you need to catch and handle. This is in the middle of what is already some potentially quite tricky code – and at some point you might throw an error and that unravels the entire stack. If there are bits of your codebase where you don’t have to worry about I/O, those bits of your codebase get much simpler, and you get much simpler flow control.

I/O in tests is just a pain, isn’t it? You’ve got to create temporary files or mock objects and account for the side effects and clean up afterwards and yuck, it’s all just a mess. If you’re not doing any I/O, if you’re just parsing around in-memory objects, byte strings, in-memory objects, lists, whatever – it’s just function calls, and testing function calls is easy.
It’s really easy to test code that’s not doing any I/O, because you don’t have to worry about any weird I/O failure states.

This is the sort of thing that’s really hard to do if you’re dealing with I/O, because you have to simulate all sorts of weird I/O failure cases and you have to hope that you’ve caught them all. When you are just testing functions that deal in pure in-memory objects, it gets a lot simpler.
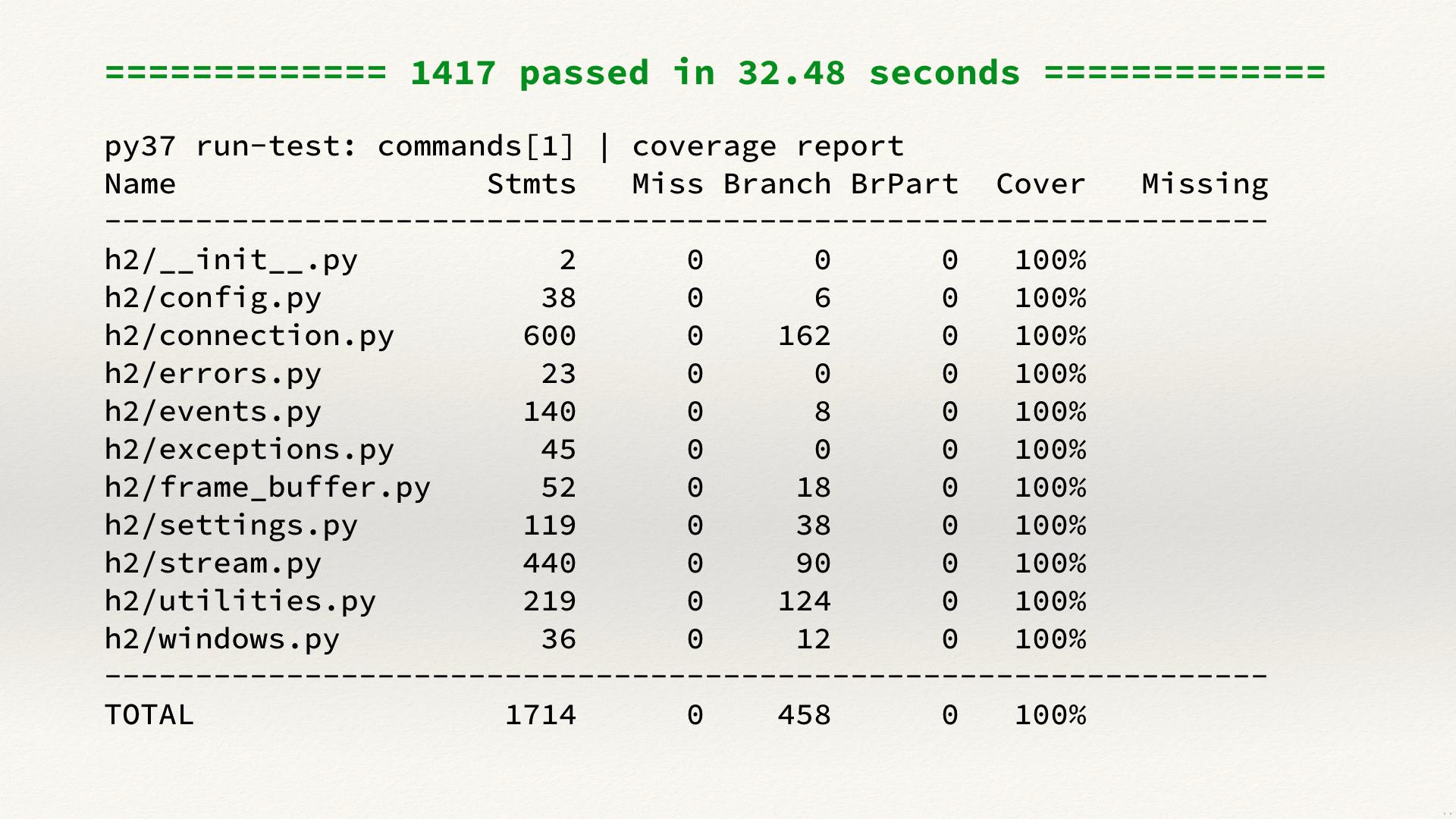
That gives us a very high degree of confidence in this code. It’s been tested very thoroughly, and several of these tests are tests using Hypothesis (a property-based testing library which runs hundreds of examples for each test), so realistically you’re getting closer to two or three thousand test cases here, all checking that this code is behaving correctly. This is a level of coverage that’s hard to achieve if you mix I/O and logic.


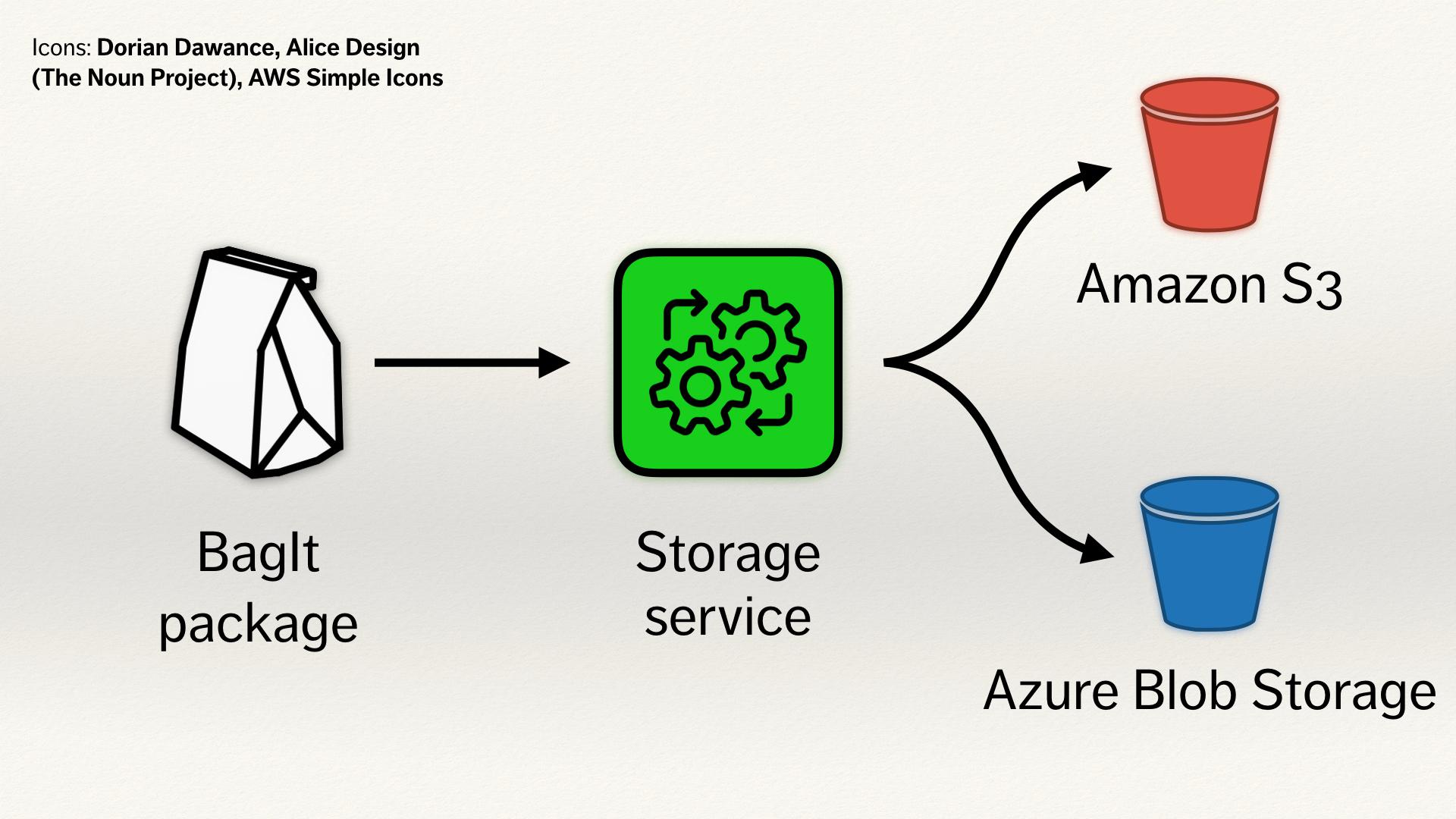
To make our archive more secure, we want multiple copies of these bags, so we write a copy of them to Azure Blob Storage. That way, if AWS goes away or closes our account or Dublin sinks into the sea, all of our data is secure.
If we had written our BagIt parsing code to only be able to talk to S3, and we’d baked that in, it would be a pain to add Azure Blob Storage. Because we wrote our code in a sans I/O way, it’s really easy to reuse that code with Azure Blob Storage. The BagIt parse doesn’t know, it just hands out bytes and says: hey, put this somewhere.



We create this Python object. We call this initiate_connection() method, and this starts building a buffer of bytes internally that we can send on the wire – but it doesn’t send those bytes anymore, just stores them in-memory. Later, we call data_to_send(), it hands us back that buffer and says, “great, here are some bytes you should send. I don’t care if you send them to a file or socket or pigeon carrier.” It washes its hands at that point – it just does all of that HTTP/2 logic entirely in-memory.
I imagine most of you aren’t working with low-level HTTP interactions, so let’s look at something higher level.

We create a CHAT_POST_MESSAGE object and a dict that contains our payload data. This library has an abstract class abc.SlackAPI, and it asks you to fill in this _request method, which processes a simple HTTP request. The class does all the work to turn your query object into an HTTP request, and then calls this _request method. It provides an implementation in Rrquests, or in curio, or in asyncio or whatever, and it’s easy to build new HTTP implementations on top of that if you need them.
The core of the library doesn’t change. That’s another nice example to look at.

The nice thing about sans I/O is that it doesn’t need to be a big, all-in-one change. You can’t take six weeks out of your sprint to re-factor all your code to be nice and sans I/O because someone at PyCon told you about it; you can make small, incremental improvements.
We’ve got a function here that’s going to load something called a tag file. It takes the name of that file, then opens that file on that disk, that yucky I/O I was talking about earlier that doesn’t connect to S3 – and then it has all the code that actually parses the content of that file. It’s treating open the file as a list of strings.

The old API is preserved, all the tests will still pass. Anybody using the old code won’t notice the difference, but this code is now a little bit more reusable. If you are getting your lines rather than from a file, say from S3, or Azure Blob Storage or somewhere else, you can feed them into the second function and you can reuse that code.
This isn’t going to completely change the way you do programming and it won’t turn the world upside-down, but it will just give you code that’s a little bit simpler, a little bit cleaner, a little bit easier to work with. I hope I’ve persuaded you that there is some virtue in writing your programs this way, given you some idea of how it’s done, and when you go back to your day jobs you’ll try it yourself.