Illustrating lifecycle transitions in Amazon S3
Because I work on a digital archive that’s hosted in the cloud, I have to think about the cost of cloud storage. How much you pay is generally determined by three questions:
How much stuff are you storing? Unsurprisingly, storing more data costs more money.
How much redundancy do you need? You could store a single copy of your data in one data centre, but if that data centre fails, your data is lost. You could store multiple copies of your data in different data centres, reducing the risk of data loss, but that costs more data.
How quickly do you need to get the data out? If you always need immediate access to your data, that costs more than if you’re willing to push it into cold storage, where retrieval might take minutes or hours.
You select how much redundancy and access you want by selecting a storage class. Each class has a price per GB stored, and that price is smaller for classes with less redundancy or slower access.
Our primary storage at work is Amazon S3, so that’s what I’m going to talk about here. We’re going to start using Azure Blob Storage soon, but I’m less familiar with storage classes there.
At time of writing, S3 has seven storage classes. You can set the storage class when you first upload an object to S3, you can manually change the storage class of an existing object, or you can create a lifecycle rule that asks S3 to move an object between storage classes automatically. For example, “move all objects in the archive/ prefix to Glacier storage after 90 days”.
We use lifecycle rules to manage a lot of content in our digital archive. For instance, all of our data is written to two buckets, and the second bucket has a lifecycle rule that moves everything to Glacier Deep Archive, Amazon’s super-cheap storage class1. It would take a while to get stuff out if we ever needed to recover from the backup, but it only costs $1/TB per month to store.
If you start exploring lifecycle rules, you eventually end up in the Amazon docs, with a diagram that explains what transitions you can set up:
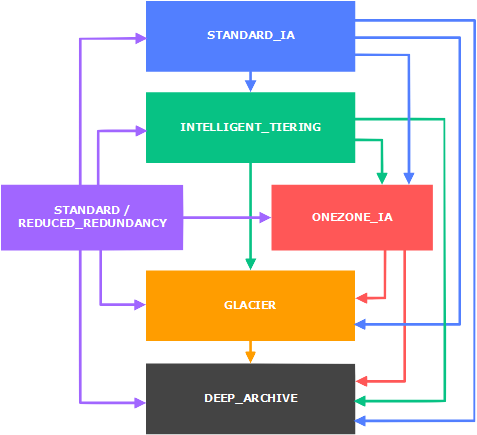
I’ve never found this diagram especially clear: objects can move left, right, up, down, sideways! I think what it’s trying to express is that you can move objects from expensive storage to cheap storage, but not the other way around.
The S3 storage tiers form a waterfall: stuff can move down, but not back up again. Here’s another illustration I came up with recently:
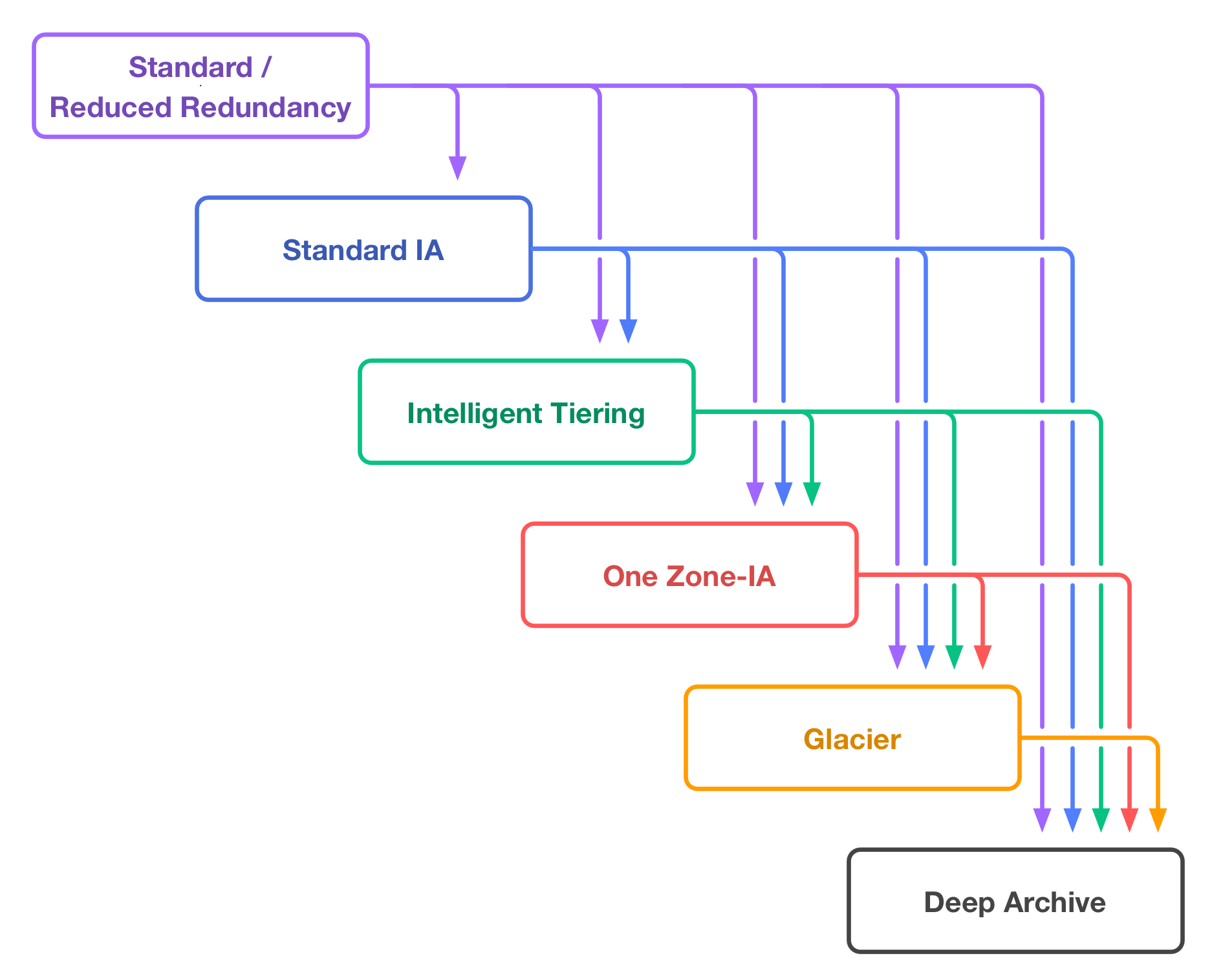
I find this version much easier to follow: the tiers form a clear hierarchy, from top to bottom. If you use S3 and would find this useful, use it the next time you need to think about storage classes.
A picture speaks a thousand words, and that’s true in software development too. I often find something much easier to understand once I’ve sketched it out, and I always keep pen and paper to hand for that exact reason. It doesn’t always have to be a fancy, pixel-perfect diagram like the one above – a napkin sketch in biro is just as good to work something out. Most of what I draw is just rectangles and arrows.
If you ever walk past my desk, you’ll see it littered in sketches, scrap paper, and coloured pens. They’re not just mess – they really do help me write better software.
We don’t write objects directly to Deep Archive, because shortly after they’re written, we read everything back out to verify it was written correctly. ↩