Building Wellcome Collection’s new archival storage service
I wrote this article while I was working at Wellcome Collection. It was originally published on their Stacks blog under a CC BY 4.0 license, and is reposted here in accordance with that license.
For the last year or so, we’ve been building a cloud-based storage service to hold Wellcome Collection’s ever-growing digital archive. This is a brand new system, designed to cope with our storage needs both now and into the future.
In this post, I’m going to explain how we built the new service, and how we migrated our existing archive from our old storage provider.

Why do we need a storage service?
Before I explain how we built the new service, it’s worth explaining why we need one at all.
Alongside our physical catalogue, we hold a substantial number of digital collections. These include:
- Born-digital material: files that started life as digital objects, say an Excel spreadsheet or an email; and
- Digitised material: digital reproductions of physical objects, like a scanned pamphlet or a photographed book.
To ensure access to our material
Wellcome’s mission is to improve human health by enabling great ideas to thrive. One way we do that is by holding and providing access to collections about the history of human health and medicine.
We want to provide access to as many and as wide a range of people as possible, and digital access is central to that goal. We need a storage service that keeps our collections safe and enables access to researchers, now and in the future.
To preserve our material in the long-term
We have an obligation as an archive and to our depositors to keep our collections safe. We can’t just throw these files on a hard drive, and hope for the best — disks fail, files get corrupted, the software to read file formats goes away. Unlike paper books, which degrade slowly and remain readable for decades, computers and their files become unusable within a matter of years.
If the digital archive was lost, many of the files are irreplaceable. In some cases, our born-digital and audiovisual files are the only remaining copy.
Audiovisual material is especially sensitive to loss: the medium of the original copy can degrade, whereas a digital file is lossless if stored safely. One of our current major projects is the digitisation of all our magnetic media — VHS tapes, Betamax, audio cassettes, and so on — before those recordings become unreadable forever.
If we want to preserve these collections, we need a storage service that can keep these files safe. That means multiple levels of protection, including checksums to ensure file integrity, backup copies of every file, and continually checking files to spot corruption.
To protect our investment
We have invested significantly in digitising our collections over the last decade. We have a responsibility to protect that investment.
Why did we build our own storage service?
There are a couple of reasons why we built our own storage service, rather than using an existing solution:
Clear ownership of the archive
When you think about archives, you have to think in the long-term. We’re not saving files for weeks or months, we’re preserving them for centuries.
We want to be sure that the files are being kept securely, and having ownership over the archive, the code and the APIs gives us a lot of control. By building a storage service ourselves, we know exactly how and where the files are stored, and what checks are in place to ensure the files are safe.
When we were building the new service, a key focus was building something as portable and understandable as possible. The files themselves will likely outlive any particular software stack, so we want to organise them in a way that remains useful long after all our code is gone.
A more human-readable storage layout
A lot of storage tools use UUIDs as their identifiers in their underlying storage. If you look at the files on disk, you see a pile of opaque filenames:

To understand the archive, you need a mapping between the UUIDs and the original filenames, which is often kept in a proprietary database. This means you’re tied to that provider, and migrating away is expensive. And if the database is lost, your archive is unusable.
When we designed our new storage service, we emphasised human-readable paths and identifiers from our existing catalogues. The files are laid out on disk in a more understandable way—you can find things in the archive from just the underlying file storage. Here’s what it looks like:

Being able to find things is important for long-term portability and understandability.
A preference for open source and open standards
We prefer using or writing open source software where possible, and building on open standards.
Using open standards allows us to use other tooling when working with the archive. For example, packages in the archive are kept in the BagIt packaging format. Lots of tools know how to understand BagIt bags, and you could use them to independently verify the files that we’re holding.
This also helps the longevity of the archive. Because we use open standards and the code is open source, it’s more likely that tools will continue to exist that can work with the archive.
Finally, developing in the open allows other people to benefit from our work. All the code we’ve written for the storage service is in a public GitHub repo, and available under an MIT license.
How did we build the storage service?
We started by coming up with a high-level design for the service.
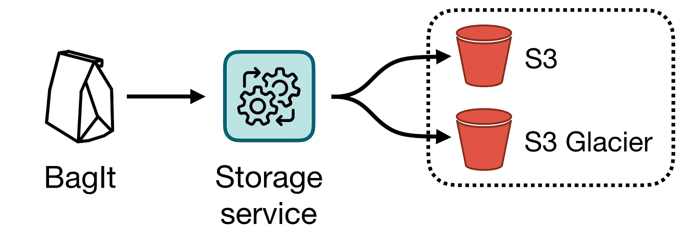
The user uploads packages in the BagIt format (a “bag”). This includes a manifest with checksums that describes all the files.
The storage service unpacks the bag, and verifies the checksums. If they are correct, it makes two copies of the entire bag: one in S3, one in S3 Glacier. Then it verifies the two copies, to check the files weren’t corrupted in transit. Assuming all is well, it reports the bag as successfully stored.
If anything goes wrong, it reports the error to the user, and explains why the bag couldn’t be stored. For example: “The checksum of cat.jpg did not match the checksum in the manifest”.
You can read our initial design document on GitHub.
So that’s the idea… but how does that become a reality? We wrote code, but what does that look like?
We reused existing knowledge to build a prototype
We’d already built a service to supply the data for our Catalogue API, so we reused a lot of the same ideas to build the initial storage service.
In particular, we built on standard AWS technologies, with the same architecture as the Catalogue API: a pipeline. The task of storing the bag is broken down into small steps, and each of these steps is a separate app. Those steps run in a line, and a bag flows from one step to the next:
![Illustration of a pipeline: four blue boxes, with arrows between them from left to right. [] ~> [] ~> [] ~> []](/images/2020/1*J5jRp-6PDsgIIE91rk7YQw_1x.png)
AWS gives us a reliable base to build on. Although it feels like we have a lot of files (~70M when we started the project), there are people who use AWS for orders of magnitude more data, and it copes fine. It’s enormously popular, so we know it’s reliable and it can scale to meet our needs.
Because we had a familiar architecture, we could reuse our existing tooling, and deploy and iterate really quickly. We could change the behaviour of each step independently, put steps in a different order, merge two steps together or break one apart, and so on. When we built the initial prototype, we were doing multiple deployments a day.
Fast iterations allowed us to improve our initial design, and get to a working prototype.
We did soak testing to find scaling issues
The prototype could store a handful of bags, but we need to store thousands of bags. And bags come in all shapes and sizes — some bags have lots of little files, or a handful of big files, or some mixture of the two.
How do we get to a point where the storage service can scale up reliably, and handle a variety of different bags?
We built an application to package the existing archive into bags, suitable to store in the storage service. Then we did regular, overnight soak tests. We’d send a sample of bags to be stored, and look at the errors that came out.
We might send 1% of the bags to be stored overnight, and in the morning there were 100 errors. We’d find the bug, fix it, deploy a new version.
The following night, we send another 1% of the bags to be stored, and in the morning there were only 50 errors. That’s an improvement! We’d find the bug, fix it, deploy a new version.
And so on. Repeating this process, we whittled down the bugs, until we could reliably send 10% of the bags in a single night and not see any errors. That gave us confidence that we could migrate 100% of the existing bags.
We ratcheted up reliability with automated tests
As we do these overnight runs, we’re finding and fixing plenty of bugs — but how do we know we’ve not introduced new bugs in the process? With automated tests.
Imagine an expected behaviour of the storage service, say: “if the bag is missing a file, then the bag should be rejected”.
Because computers are deterministic (mostly), we can write an automated test that checks this behaviour, and tells us if the code is broken. “Send a bag with a missing file. Is the bag rejected?” When the computer runs the test, if it doesn’t see the expected behaviour, the test fails, highlighting the error.
Every time we found a new bug, we wrote a new test: “this bug should not occur”. When the test passes, we know the bug is fixed. As long as the test keeps passing, we know that particular bug hasn’t been reintroduced.
And then we run all our tests every time we change code. Every proposed change to our repository is tested automatically by Travis CI, which gives a green tick (all the tests passed) or a red cross (one of the tests failed). If we get a red cross, we know we have more work to do.
The tests give us a safety net against mistakes, and every passing test gives us more confidence that the code is behaving correctly. As we write more tests, we can ratchet up our confidence in the service.
Is the current code bug-free? Almost certainly not — but when we find bugs, we can fix them and deploy new versions quickly.
Migrating the digitised archive
p>Once we’ve done our reliability testing, we needed to migrate all our content out of the old storage. We started by migrating the digitised archive, which is the majority of our files. How did that work?
- We turned off writes of new files into the old storage —so we only have to migrate a static collection, not something that’s changing under our feet. We had to coordinate with the digitisation team, to minimise the disruption to their workflow.
- We created a bag for every item in the old collection — 260k items, so there were 260k bags.
- We stored every single one of those bags in the storage service, with its internal checks and verifications that bags were correctly stored.
- Then we ran a whole sequence of extra checks, comparing content in the old and the new storage. Had we created the correct bags? Had we sorted the files correctly? Had we missed any images? And so on.
- Once we were happy everything had migrated successfully, we updated the Library website to read images from the new storage. If you’ve looked at any of our digitised content since last October, it was served from the new storage service!
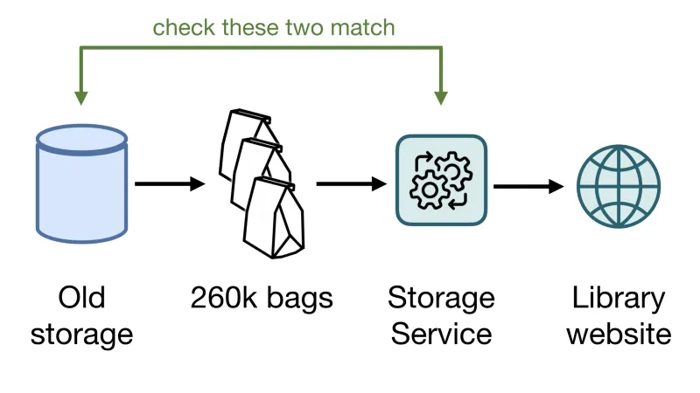
Overall the migration was very successful, and nobody noticed the switchover when it happened. It validated a lot of our reliability testing: we managed to store a decade’s worth of digitisation output in a fortnight.
Shortly afterwards, we reenabled writes, so our digitisation team could start saving new digitisation projects — but now they were being written into our new storage service, not the old storage.
State of the storage service
At the time of writing, we have all the migrated digitised content, and we’ve been using the storage service to store newly digitised files since October. We also have most of the uncatalogued born-digital material (although that’s a tiny fraction of the archive).
Here are some headline numbers:

The estimated annual cost includes both the S3 storage, and the compute resource required to run the service. This is substantially cheaper than the alternatives we considered.
Part of the saving is because the storage service is only running when there are bags to store — it scales up to process the new bags, then scales down again afterwards. This makes it very efficient, and means we’re not paying for compute resource that we’re not using.
This doesn’t include the cost of developer time to support the service — but at the moment, it’s reliable enough that support is a small cost. Since we finished the digitised content migration in October, we haven’t had any bugs or outages, and we’ve barely had to do any work on it.
What’s next?
Bring in our born-digital content
We’ve already got our digitised content in the storage service, and now we’re migrating our born-digital content to live in the same place.
We’re setting up Archivematica as our born-digital workflow manager, and we’ve made changes to Archivematica so it can write packages directly into our storage service.
Better support for deleting files
This might seem like an odd thing to want — we’re building a service to preserve files, so why do we want to delete things?
The answer: personal data.
After somebody has donated born-digital material to our collections, we do a process of sensitivity review. If we discover a collection contains large amounts of personal data, we might choose to remove those files from the archive.
The current process for deleting files is very manual, and we’d like to have better automation and auditing of deletions.

Replication into Microsoft Azure in Amsterdam
The current storage service has two copies of every file: one in S3, one in S3 Glacier, both in Amazon’s eu-west-1 region.
This isn’t ideal — it’s a single geographic location and a single cloud provider. If Amazon closes our account or there’s an accident at the data centre, we’d lose the entire archive.
For extra redundancy, we’d like to have a third copy of our data. We’re planning to add another replica in Microsoft’s Azure data centre in Amsterdam.
This will become part of the storage process — every time we store a new bag, we’ll make a copy in Azure before reporting the bag as successfully stored.
Better visibility of statistics about the files we’re storing
We want to be able to aggregate information across our collections. The archives contain millions of files, and a single person could never read all of them — but a machine can. You might ask questions like:
- How many images did we digitise last month?
- What file formats are we holding? Are any of those formats about to go out-of-support?
- How big are those files?
We’re just beginning to provide this sort of data internally, and we’re excited to see how people use it!
Help other people learn from the storage service
All our code is open source and in a public repo, and we hope other people can learn from what we’ve done.
I’ve been writing blog posts about some standalone parts of the code that might be usable in other contexts (example, example, example), and I expect to keep doing that.
We’re also trying to be better about documentation, so the repo will hopefully become easier to browse and understand soon.
Our new storage service gives us a reliable, robust platform for the next decade of digital archives at Wellcome. Lots of people worked really hard to get it in place, and we’re excited to see what we can build on top of it.
If you’d like to learn more:
- The code is on GitHub at wellcomecollection/storage-service
- The original design document is available as an RFC
Thanks to Alexandra Eveleigh, Robert Kenny, Jenn Phillips-Bacher, Tom Scott and Jonathan Tweed for their help writing this post.