Storing multiple, human-readable versions of BagIt bags
I wrote this article while I was working at Wellcome Collection. It was originally published on their Stacks blog under a CC BY 4.0 license, and is reposted here in accordance with that license.
We made fetch.txt happen.
In my last post, I talked about the general ideas behind our new archival storage service.
A brief reminder: we store our digital archive in BagIt “bags”. A bag is a collection of related files: for example, all the digitised images from a single book. BagIt is an open format developed by the Library of Congress for packaging files, which includes manifests and checksums that describe the files in a bag – so we can verify files have been transferred and stored successfully. The bags we store are produced by our workflow systems: Goobi for digitised material, Archivematica for born-digital material.
In the post, I had an illustration showing how we store files on disk in a human-readable way, including the fact that we can store multiple versions of a bag. The BagIt spec doesn’t include a system for versioning – we had to design our own approach – and several people asked how it works.
In this post, I’m going to explain the versioning of the storage service in more detail. We have an elegant system based on the fetch.txt feature of the BagIt spec.
Author’s note: my previous post was a general overview; this post focuses on a more specific implementation detail. I enjoy this sort of deep dive, but it may not be for everyone. At the very least, grab a warm drink and a biscuit before you start. Treat yourself.
The problem
The storage service allows us to store a collection of files as a single bag. Sometimes we want to change a bag after it was initially stored. For example, we might be editing the metadata, or fixing the incorrect rotation of an image.
We want to record these changes, but also to preserve the provenance of the original files. Whatever mechanism we came up with for storing updates had to preserve the older versions.
We came up with the following requirements:
You can get back any version, not just the latest one
If you store a bag (call that “version 1”) and then later store an updated bag (“version 2”), you should be able to request either version 1 or version 2, and get back the corresponding files.
You can request the latest version of a bag
Although storing multiple versions of a bag is important for historical provenance, the distinction doesn’t matter to every user. It should be possible to get the latest version without having to know how many other versions have been stored.
We can find the version of a bag at a specific time
Suppose somebody downloaded the latest version of a bag at a particular time, but didn’t take note of the version. We should be able to work out which version of the bag they were looking at.
Versions should make sense to people
If you have a list of all the versions of a bag, it should be obvious which is the latest version, and what order the versions were stored in.
For example, if I tell you the versions are “v1”, “v2” and “v3”, you can tell that’s the order they were stored in. Compare to something like the version-control system Git, which identifies changes with SHA-1 hashes. Is 7faf7ef newer than 6fe2b1f? Unless you can understand the Git database, it’s impossible to say.
Technical requirements
The requirements above describe how the system should behave; we also had some requirements based on how we’d implemented the rest of the storage service:
The versions should be laid out in a human-readable way on disk
We know these files have to last a long time, so the versioning scheme should be clear from the structure of the files on disk. Everything I described above (get back any version, get the latest version, work out the ordering) should be possible with nothing but the file layout.
Further, it should be clear that this is a versioning system. You should be able to tell, say, that b1234/v1 and b1234/v2 are two versions of the same bag, not two different bags.
We should support partial updates
Suppose v1 of a bag contains 1000 files, and we want to update a single file. When we record the update, it should be possible to store just the updated file, and not keep extra copies of all the unchanged files.
Once a version is written, it’s immutable
If we’ve stored and verified v1, trying to store v2 shouldn’t compromise the integrity of the v1 bag.
We don’t want to overwrite an already-stored bag. This introduces lots of complexity and potential for error: what if you try to store an update, the update fails, and then you roll back to the previous version and that fails also? You’ve broken the integrity of your archive. If new versions are strictly additive, and never affect previously-stored files, we avoid this failure mode.
The solution
The idea of storing partial updates helped us find the first part of the solution: using the fetch.txt in a BagIt package.
The fetch.txt is a mapping of files paths in the bag to URLs. It tells the person reading the bag that a file hasn’t been included in this copy of the bag; they have to go and fetch it from elsewhere. The file is still recorded in the manifest (so it has a checksum you can verify), but you don’t have a complete bag until you’ve downloaded all the files.
Here’s an example of a fetch.txt:
https://example.org/~lexie/report.pdf 1729 data/report.pdfThis tell us that the file data/report.pdf isn’t included in this copy of the bag – we should download it from https://example.org/~lexie/report.pdf. (The number 1729 is the size of the remote file. It’s an optional field.)
Using a fetch.txt allows you to send a bag with “holes”, which saves disk space and network bandwidth, but at a cost – we’re now relying on the remote location to remain available. From a preservation standpoint, this is scary! If example.org went away, this bag would be broken. I know some people don’t use fetch.txt in their digital archives for exactly this reason.
But a URL can point anywhere – including back into our storage service. Because the primary copy of our files is in S3, we can construct a fetch.txt with an S3 URL. For example:
s3://wellcomecollection-storage/examples/lexie/v1/data/report.pdf 1729 report.pdfSo we added a rule: you can include a fetch.txt, but it can only refer to files within the storage service.
Later, we strengthened the rule: a fetch.txt can only refer to files in previous versions of the same bag.
The first rule means the archive is self-contained, and we’re not relying on the long-term availability of other systems to maintain the archive’s integrity. The second rule keeps it simple: you can only have back-references within a single bag, not among all bags. This avoids a twisted mess of spaghetti references!
An aside: what is “the same bag”?
I’ve talked about keeping multiple versions of “the same bag”, but what does that look like in practice? How does the storage service distinguish between two versions of the same bag, or two different bags with one version each?
A BagIt bag can include a metadata file bag-info.txt. One of the fields in this file is External-Identifier, which is “a sender-supplied identifier for the bag”. Although External-Identifier is optional in the BagIt spec, our storage service requires that you give a value here: for example, an identifier from our library catalogue. Bags are then grouped based on their external identifier.
If two bags have the same external identifier, we treat them as two versions of the same bag. If two bags have different external identifiers, we treat as two different bags with one version each.
Laying out different versions of a bag on disk
An identifier in the storage service is made of three parts:
- The storage space, e.g. “digitised” or “born-digital”. This is the broad category of a bag.
- The external identifier, as supplied in the bag-info.txt. This is usually the identifier from another system.
- The version, which is generated by the storage service. It’s an auto-incrementing value: v1, v2, v3, and so on.
The path to a bag is constructed as follows:
{space}/{external identifier}/{version}For example, if we had three versions of a bag in the “digitised” space with external identifier “b31497652”, we’d have the following folder structure:
digitised/
└── b31497652/
├── v1/
├── v2/
└── v3/All the versions for a given (space, external identifier) are under the same folder. We chose to add a “v” prefix to make it more obvious that the folders correspond to versions; an earlier design used numerals alone.
A worked example
The best way to understand how the versioning behaves is to see a few examples. Let’s see how you might update a bag.
When you store the first version of a bag, you have to include all the files. Let’s create a bag with two files: cat.jpg and dog.jpg. The bag manifest file has two entries, and there is no fetch.txt file. This bag is stored as v1:

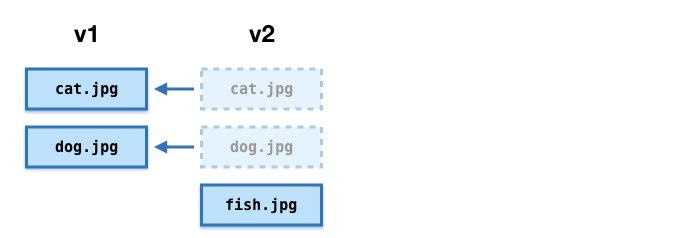
Now we want to add a new file. Suppose we want to add fish.jpg.
We could upload a complete copy of the bag again, or we could upload a partial update. This bag includes a manifest with three entries (cat.jpg, dog.jpg, fish.jpg), a fetch.txt with two entries (cat.jpg in v1, dog.jpg in v1), and a copy of the new image. This bag is stored v2:
Next, suppose we want to delete a file. Maybe dog.jpg doesn’t really belong in this bag, and we’d like to remove it.
We create a bag with a manifest file with two entries (cat.jpg, fish.jpg) and a fetch.txt with two entries that point back to previous versions. There’s no reference to dog.jpg anywhere in this bag. This becomes v3:
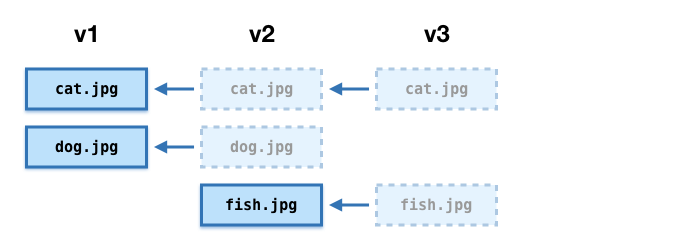
The dog.jpg file is still available in v2, but it’s not referenced in v3 so it’s not part of that version of the bag.
Finally, suppose we want to modify a file. Maybe we have a new, cuter picture of cat.jpg.
We create a fourth bag. The manifest has two entries, the fetch.txt has a single entry (pointing back to the unmodified copy of fish.jpg), and the bag has the new copy of cat.jpg. This becomes v4:
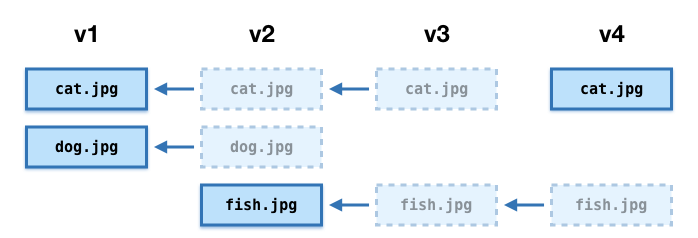
We’ve now stored four versions of this bag, and we could retrieve a complete copy of any version – but we’ve only had to store four files, not nine.
In practice, bags contain hundreds or thousands of files, so there are significant storage savings if we do partial updates.
If you want to do a more complex update (for example, adding some new files and updating some others), you can combine these operations to construct the appropriate bag.
Each of these versions has been through the same verification process:
- We check the checksums in the manifest match the actual files, whether the file is included in the uploaded bag, or stored in a previous version and referenced in the fetch.txt.
- If the entry in the fetch.txt includes the size of the file, we check the size matches.
- We check that every URL in the fetch.txt only refers to previous versions of the same bag. Anything else –an HTTP link, an FTP URI, a file in a bag with a different external identifier – gets rejected.
What about automatic deduplication?
To get any savings in storage cost, you need to de-duplicate identical files between different versions, like we’re doing with fetch.txt.
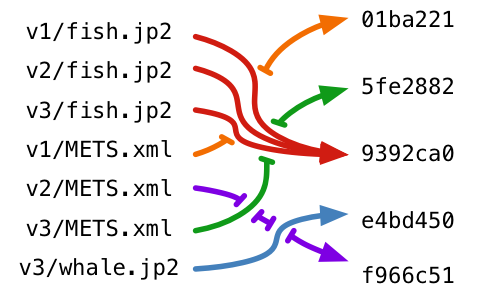
To maximise your savings, you’d automatically deduplicate any files that get stored. Some systems do this – for example, Git stores files based on their SHA-1 hash of their content. If you save the same file multiple times, it only saves a single copy. This is more efficient for storage, but Git has to maintain a set of pointers between the original filenames and the SHA-1 hashes, which breaks the idea that our files should be stored in a clear, human-understandable way. (If you’re interested in how Git stores files internally, you might enjoy my Plumber’s Guide to Git.)
We could identify duplicate files in previous versions, and create an appropriate fetch.txt ourselves, but this would be more complicated. The storage service is deliberately simple – simple code is easier to implement, has less room for bugs, and less risk of accidental data loss or corruption.
We chose not to automatically deduplicate files in the storage service. We rely on the user to tell us about duplicate files by uploading an appropriate fetch.txt. If they upload duplicate files without a fetch.txt, we’ll just store all the files a second time. Although this is slightly less efficient, it reduces the risk of corruption or error.
The storage service has a simple rule: it stores exactly what bytes you provide; no more, no less. If you supply a concrete copy of the same file in multiple versions, we’ll store a concrete copy of that file in every version.
This also allows for easier external verification. If you upload a bag to the storage service, you can download your bag later and check the bytes are exactly what you uploaded. If the service started editing your files, that sort of verification would be much harder.
A BagIt alternative with first-class versioning: OCFL
Our storage service is based heavily on the BagIt format. BagIt doesn’t have built-in support for versioning – what I’ve described is a convention we created, not part of the spec.
Since then, there have been several draft specifications for the Oxford Common File Layout (OCFL), another convention for storing digital files in a structured, human-readable way. Unlike BagIt, OCFL has first-class support for versioning as part of the spec. The folder layout for versions is similar to our design. (I can’t remember if this was a simultaneous invention, or if we’d read the OCFL draft spec when we designed our system.)
If you’re interested in versioning your archive, it’s worth considering the ideas in the OCFL spec.
This solution arose organically, because we could iterate quickly on our original prototype. Rather than designing the whole system upfront, we could experiment with different approaches – at least half a dozen designs, probably more.
Using fetch.txt to handle BagIt versions gives us simple, human-readable versioning for bags. We can look up any version, use partial updates to reduce storage costs, and the archive is always self-contained. Since we started using the storage service last October, we already have over 1500 bags stored with multiple versions, and that number will only grow.
Thanks to Robert Kenny, Jamie Parkinson, and Tom Scott for their help writing this post.