What I learnt about making websites by reading two thousand web pages
Over the past year, I built a web archive of over two thousand web pages – my own copy of everything I’ve bookmarked in the last fifteen years. I saved each one by hand, reading and editing the HTML to build a self-contained, standalone copy of each web page.
These web pages were made by other people, many using tools and techniques I didn’t recognise. What started as an exercise in preservation became an unexpected lesson in coding: I was getting a crash course in how the web is made. Reading somebody else’s code is a great way to learn, and I was reading a lot of somebody else’s code.
In this post, I’ll show you some of what I learnt about making websites: how to write thoughtful HTML, new-to-me features of CSS, and some quirks and relics of the web.
This article is the third in a four part bookmarking mini-series:
- Creating a static site for all my bookmarks – why I bookmark, why I use a static site, and how it works.
- Building a personal archive of the web, the slow way – how I built a web archive by hand, the tradeoffs between manual and automated archiving, and what I learnt about preserving the web.
- Learning how to make websites by reading two thousand web pages (this article)
- My favourite websites from my bookmark collection – websites that change randomly, that mirror the real world, or even follow the moon and the sun, plus my all-time favourite website design.
Interesting HTML tags
I know I’ve read a list of HTML tags in reference documents and blog posts, but there are some tags I’d forgotten, misunderstood, or never seen used in the wild. Reading thousands of real-world pages gave me a better sense of how these tags are actually used, and when they’re useful.
The <aside> element
MDN describes <aside> as “a portion of a document whose content is only indirectly related to the document’s main content”. That’s vague enough that I was never quite sure when to use it.
In the web pages I read, I saw <aside> used in the middle of larger articles, for things like ads, newsletter sign ups, pull quotes, or links to related articles. I don’t have any of those elements on my site, but now I have a stronger mental model of where to use <aside>. I find concrete examples more useful than abstract definitions.
I also saw a couple of sites using the <ins> (inserted text) element for ads, but I think <aside> is a better semantic fit.
The <mark> element
The <mark> element highlights text, typically with a yellow background. It’s useful for drawing visual attention to a phrase, and I suspect it’s helpful for screen readers and parsing tools as well.
I saw it used in Medium to show reader highlights, and I’ve started using it in code samples when I want to call out specific lines.
The <section> element
The <section> tag is a useful way to group content on a page – more meaningful than a generic <div>. I’d forgotten about it, although I use similar tags like <article> and <main>. Seeing it used across different sites reminded me it exists, and I’ve since added it to a few projects.
The <hgroup> (heading group) element
The <hgroup> tag is for grouping a heading with related metadata, like a title and a publication date:
<hgroup>
<h1>All about web bookmarking</h1>
<p>Posted 16 March 2025</p>
</hgroup>This is another tag I’d forgotten, which I’ve started using for the headings on this site.
The <video> element
The <video> tag is used to embed videos in a web page. It’s a tag I’ve known about for a long time – I still remember reading Kroc Camen’s article Video is for Everybody in 2010, back when Flash was being replaced as dominant way to watch video on the web.
While building my web archive, I replaced a lot of custom video players with <video> elements and local copies of the videos. This was my first time using the tag in anger, not just in examples.
One mistake I kept making was forgetting to close the tag, or trying to make it self-closing:
<!-- this is wrong -->
<video controls src="videos/Big_Buck_Bunny.mp4"/>It looks like <img>, which is self-closing, but <video> can have child elements, so you have to explicitly close it with </video>.
The <progress> indicator element
The <progress> element shows a progress indicator. I saw it on a number of sites that publish longer articles – they used a progress bar to show you how far you’d read.
<label for="file">Progress:</label> <progress id="file" max="100" value="70">70%</progress>.
I don’t have a use for it right now, but I like the idea of getting OS-native progress bars in HTML – no custom JavaScript or CSS required.
The <base> element
The <base> element specifies the base URL to use for any relative URLs in a document. For example, in this document:
<base href="https://example.com/">
<img src="/pictures/cat.jpg">the image will be loaded from https://example.com/pictures/cat.jpg.
It’s still not clear to me when you should use <base>, or what the benefits are (aside from making your URLs a bit shorter), but it’s something I’ll keep an eye out for in future projects.
Clever corners of CSS
The CSS @import rule
CSS has @import rules, which allow one stylesheet to load another:
@import "fonts.css";I’ve used @import in Sass, but I only just realised it’s now a feature of vanilla CSS – and one that’s widely used. The CSS for this website is small enough that I bundle it into a single file for serving over HTTP (a mere 13KB), but I’ve started using @import for static websites I load from my local filesystem, and I can imagine it being useful for larger projects.
One feature I’d find useful is conditional imports based on selectors. You can already do conditional imports based on a media query (“only load these styles on a narrow screen”) and something similar for selectors would be useful too (for example, “only load these styles if a particular class is visible”). I have some longer rules that aren’t needed on every page, like styles for syntax highlighting, and it would be nice to load them only when required.
[attr$=value] is a CSS selector for suffix values
While reading Home Sweet Homepage, I found a CSS selector I didn’t understand:
img[src$="page01/image2.png"] {
left: 713px;
top: 902px;
}This $= syntax is a bit of CSS that selects elements whose src attribute ends with page01/image2.png. It’s one of a several attribute selectors that I hadn’t seen before – you can also match exact values, prefixes, or words in space-separated lists. You can also control whether you want case-sensitive or -insensitive matching.
You can create inner box shadows with inset
Here’s a link style from an old copy of the Entertainment Weekly website:
a { box-shadow: inset 0 -6px 0 #b0e3fb; }A link on EW.com
The inset keyword was new to me: it draws the shadow inside the box, rather than outside. In this case, they’re setting offset-x=0, offset-y=-6px and blur-radius=0 to create a solid stripe that appears behind the link text – like a highlighter running underneath it.
If you want something that looks more shadow-like, here are two boxes that show the inner/outer shadow with a blur radius:
I don’t have an immediate use for this, but I like the effect, and the subtle sense of depth it creates. The contents of the box with inner-shadow looks like it’s below the page, while the box with outer-shadow floats above it.
For images that get bigger, cursor: zoom-in can show a magnifying glass
On gallery websites, I often saw this CSS rule used for images that link to a larger version:
cursor: zoom-in;Instead of using cursor: pointer; (the typical hand icon for links), this shows a magnifying glass icon – a subtle cue that clicking will zoom or expand the image.
Here’s a quick comparison:
 | the default cursor is typically an arrow |
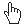 | the pointer cursor is typically a hand, used to indicate links |
 | the zoom-in cursor is a magnifying glass with a plus sign, suggesting “click to enlarge” |
I knew about the cursor property, but I’d never thought to use it that way. It’s a nice touch, and I want to use it the next time I build a gallery.
Writing thoughtful HTML
The order of elements
My web pages have a simple one column design: a header at the top, content in the middle, a footer at the bottom. I mirror that order in my HTML, because it feels a natural structure.
I’d never thought about how to order the HTML elements in more complex layouts, when there isn’t such a clear direction. For example, many websites have a sidebar that sits alongside the main content. Which comes first in the HTML?
I don’t have a firm answers, but reading how other people structure their HTML got me thinking. I noticed several pages that put the sidebar at the very end of the HTML, then used CSS to position it visually alongside the content. That way, the main content appears earlier in the HTML file, which means it can load and become readable sooner.
It’s something I want to consider next time I’m building a more complex page.
Comments to mark the end of large containers
I saw a lot of websites (mostly WordPress) that used HTML comments to mark the end of containers with a lot of content. For example:
<div id="primary">
<main id="main">
…
</main><!-- #main -->
</div><!-- #primary -->These comments made the HTML much easier to read – I could see exactly where each component started and ended.
I like this idea, and I’m tempted to use it in my more complex projects. I can imagine this being especially helpful in template files, where HTML is mixed with template markup in a way that might confuse code folding, or make the structure harder to follow.
The data-href attribute in <style> tags
Here’s a similar idea: I saw a number of sites set a data-href attribute on their <style> tags, as a way to indicate the source of the CSS. Something like:
<style data-href="https://example.com/style.css"></style>I imagine this could be useful for developers working on that page, to help them find where they need to make changes to that <style> tag.
Translated pages with <link rel="alternate"> and hreflang
I saw a few web pages with translated versions, and they used <link> tags with rel="alternate" and an hreflang attribute to point to those translations. Here’s an example from a Panic article, which is available in both US English and Japanese:
<link rel="alternate" hreflang="en-us" href="https://blog.panic.com/firewatch-demo-day-at-gdc/">
<link rel="alternate" hreflang="ja" href="https://blog.panic.com/ja/firewatch-demo-day-at-gdc-j/">This seems to be for the benefit of search engines and other automated tools, not web browsers. If your web browser is configured to prefer Japanese, you’d see a link to the Japanese version in search results – but if you open the English URL directly, you won’t be redirected.
This makes sense to me – translations can differ in content, and some information might only be available in one language. It would be annoying if you couldn’t choose which version you wanted.
Panic’s article includes a third <link rel="alternate"> tag:
<link rel="alternate" hreflang="x-default" href="https://blog.panic.com/firewatch-demo-day-at-gdc/">This x-default value is a fallback, used when there’s no better match for the user’s language. For example, if you used a French search engine, you’d be directed to this URL because there isn’t a French translation.
Almost every website I’ve worked has been English-only, so internationalisation is a part of the web I know very little about.
Fetching resources faster with <link rel="preload">
I saw a lot of websites that with <link rel="preload"> tags in their <head>. This tells the browser about resources that will be needed soon, so it should start fetching them immediately.
Here’s an example from this site:
<link rel="preload" href="https://alexwlchan.net/theme/white-waves-transparent.png" as="image" type="image/png"/>That image is used as a background texture in my CSS file. Normally, the browser would have to download and parse the CSS before it even knows about the image – which means a delay before it starts loading it. By preloading the image, the browser can begin downloading the image in parallel with the CSS file, so it’s already in progress when the browser reads the CSS.
The difference is probably imperceptible on a fast connection, but it is a performance improvement – and as long as you scope the preloads correctly, there’s little downside. (Scoping means ensuring you don’t preload resources that aren’t used).
I saw some sites use DNS prefetching, which is a similar idea. The rel="dns-prefetch" attribute tells the browser about domains it’ll fetch resources from soon, so it should begin DNS resolution early. The most common example was websites using Google Fonts:
<link rel="dns-prefetch" href="https://fonts.googleapis.com/" />I only added preload tags to my site a few weeks ago. I’d seen them in other web pages, but I didn’t appreciate the value until I wrote one of my own.
Quirks and relics
There are still lots of <!--[if IE]> comments
Old versions of Internet Explorer supported conditional comments, which allowed developers to add IE-specific behaviour to their pages. Internet Explorer would render the contents of the comment as HTML, while other browsers ignored it. This was a common workaround for deficiencies in IE, when pages needed specific markup or styles to render correctly.
Here’s an example, where the developer adds an IE-specific style to fix a layout issue:
<!--[if IE]>
<style>
/* old IE unsupported flexbox fixes */
.greedy-nav .site-title {
padding-right: 3em;
}
</style>
<![endif]-->Developers could also target specific versions of IE:
<!--[if lte IE 7]><link rel="stylesheet" href="/css/ie.css"><![endif]-->Some websites even used conditional comments to display warnings and encourage users to upgrade, like this message which that’s still present on the RedMonk website today:
<!--[if IE]>
<div class="alert alert-warning">
You are using an <strong>outdated</strong> browser. Please <a href="http://browsehappy.com/">upgrade your browser</a> to improve your experience.
</div>
<![endif]-->This syntax was already disappearing by the time I started building websites – support for conditional comments was removed in Internet Explorer 10, released in 2012, the same year that Google Chrome became the most-used browser worldwide. I never wrote one of these comments, but I saw lots of them in archived web pages.
These comments are a relic of an earlier web. Most websites have removed them, but they live on in web archives, and in the memories of web developers who remember the bad old days of IE6.
Templates in <script> tags with a non-standard type attribute
I came across a few pages using <script> tags with a type attribute that I didn’t recognise. Here’s a simple example:
<script type="text/x-handlebars-template" id="loading_animation">
<div class="loading_animation pulsing <%= extra_class %> {{ extra_class }}"><div></div></div>
</script>Browsers ignore <script> tags with an unrecognised type – they don’t run them, and they don’t render their contents. Developers have used this as a way to include HTML templates in their pages, which JavaScript could extract and use later.
This trick was so widespread that HTML introduced a dedicated <template> tag element for the same purpose. It’s been in all the major browsers for years, but there are still instances of this old technique floating around the web.
Browsers won’t load external file:// resources from file:// pages
Because my static archives are saved as plain HTML files on disk, I often open them directly using the file:// protocol, rather than serving them over HTTP. This mostly works fine – but I ran into a few cases where pages behave differently depending on how they’re loaded.
One example is the SVG <use> element. Some sites I saved use SVG sprite sheets for social media icons, with markup like:
<use href="sprite.svg#logo-icon"></use>This works over http://, but when loaded via file://, it silently fails – the icons don’t show up.
This turns out to be a security restriction. When a file:// page tries to load another file:// resource, modern browsers treat it as a cross-origin request and block it. This is to prevent a malicious downloaded HTML file from snooping around your local disk.
It took me a while to figure this out. At first, all I got was a missing icon. I could see an error in my browser console, but it was a bit vague – it just said I couldn’t load the file for “security reasons”.
Then I dropped this snippet into my dev tools console:
fetch("sprite.svg")
.then(response => console.log("Fetch succeeded:", response))
.catch(error => console.error("Fetch failed:", error));It gave me a different error message, one that explicitly mentioned cross-origin requesting sharing: “CORS request not http”. This gave me something I could look up, and led me to the answer.
This is easy to work around – if I spin up a local web server (like Python’s http.server), I can open the page over HTTP and everything loads correctly.
What does GPT stand for in attributes?
Thanks to the meteoric rise of ChatGPT, I’ve come to associate the acronym “GPT” with large language models (LLMs) – it stands for Generative Pre-trained Transformer.
That means I was quite surprised to see “GPT” crop up on web pages that predate the widespread use of generative AI. It showed up in HTML attributes like this:
<div id="div-gpt-ad-1481124643331-2">I discovered that “GPT” also stands for Google Publisher Tag, part of Google’s ad infrastructure. I’m not sure exactly what these tags were doing – and since I stripped all the ads out of my web archive, they’re not doing anything now – but it was clearly ad-related.
What’s the instapaper_ignore class?
I found some pages that use the instapaper_ignore CSS class to hide certain content. Here’s an example from an Atlantic article I saved in 2017:
<aside class="pullquote instapaper_ignore">
Somewhere at Google there is a database containing 25 million books and nobody is allowed to read them.
</aside>Instapaper is a “read later” service – you save an article that looks interesting, and later you can read it in the Instapaper app. Part of the app is a text parser that tries to extract the article’s text, stripping away junk or clutter.
The instapaper_ignore class is a way for publishers to control what that parser includes. From a blog post in 2010:
Additionally, the Instapaper text parser will support some standard CSS class names to instruct it:
instapaper_body: This element is the body container.instapaper_ignore: These elements, when inside the body container, should be removed from the text parser’s output.
In this example, the element is a pull quote – a repeated line from the article, styled to stand out. On the full web page, it works. But in the unstyled Instapaper view, it would just look like a duplicate sentence. It makes sense that the Atlantic wouldn’t want it to appear in that context.
Only a handful of pages I’ve saved ever used instapaper_ignore, and even fewer are still using it today. I don’t even know if Instapaper’s parser still looks for it.
This stood out to me because I was an avid Instapaper user for a long time. I deleted my account years ago, and I don’t hear much about “read later” apps these days – but then I stumble across a quiet little relic like this, buried in the HTML.
I found a bug in the WebKit developer tools
Safari is my regular browser, and I was using it to preview pages as I saved them to my archive. While I was archiving one of Jeffrey Zeldman’s posts, I was struggling to understand how some of his CSS worked. I could see the rule in my developer tools, but I couldn’t figure out why it was behaving the way it was.
Eventually, I discovered the problem: a bug in WebKit’s developer tools was introducing whitespace that changed the meaning of the CSS.
For example, suppose the server sends this minifed CSS rule:
body>*:not(.black){color:green;}WebKit’s dev tools prettify it like this:
body > * :not(.black) {
color: green;
}But these aren’t equivalent!
- The original rule matches direct children of
<body>that don’t have theblackclass. - The prettified version matches any descendant of
<body>that doesn’t have theblackclass and that isn’t a direct child.
The CSS renders correctly on the page, but the bug means the Web Inspector can show something subtly wrong. It’s a formatting bug that sent me on a proper wild goose chase.
This bug remains unfixed – but interestingly, a year later, that particular CSS rule has disappeared from Zeldman’s site. I wonder if it caused any other problems?
Closing thoughts
The web is big and messy and bloated, and there are lots of reasons to be pessimistic about the state of modern web development – but there are also lots of people doing cool and interesting stuff with it. As I was reading this mass of HTML and CSS, I had so many moments where I thought “ooh, that’s clever!” or “neat!” or “I wonder how that works?”. I hope that as you’ve read this post, you’ve learnt something too.
I’ve always believed in the spirit of “view source”, the idea that you can look at the source code of any web page and see how it works. Although that’s become harder as more of the web is created by frameworks and machines, this exercise shows that it’s clinging on. We can still learn from reading other people’s source code.
When I set out to redo my bookmarks, I was only trying to get my personal data under control. Learning more about front-end web development has been a nice bonus. My knowledge is still a tiny tip of an iceberg, but now it’s a little bit bigger.
I know this post has been particularly dry and technical, so next week I’ll end this series on a lighter note. I’ll show you some of my favourite websites from my bookmarks – the fun, the whimsical, the joyous – the people who use the web as a creative canvas, and who inspire me to make my web presence better.