A Plumber’s Guide to Git: Conclusion
Well done for getting this far!
Let’s recap what we’ve learnt throughout the workshop:
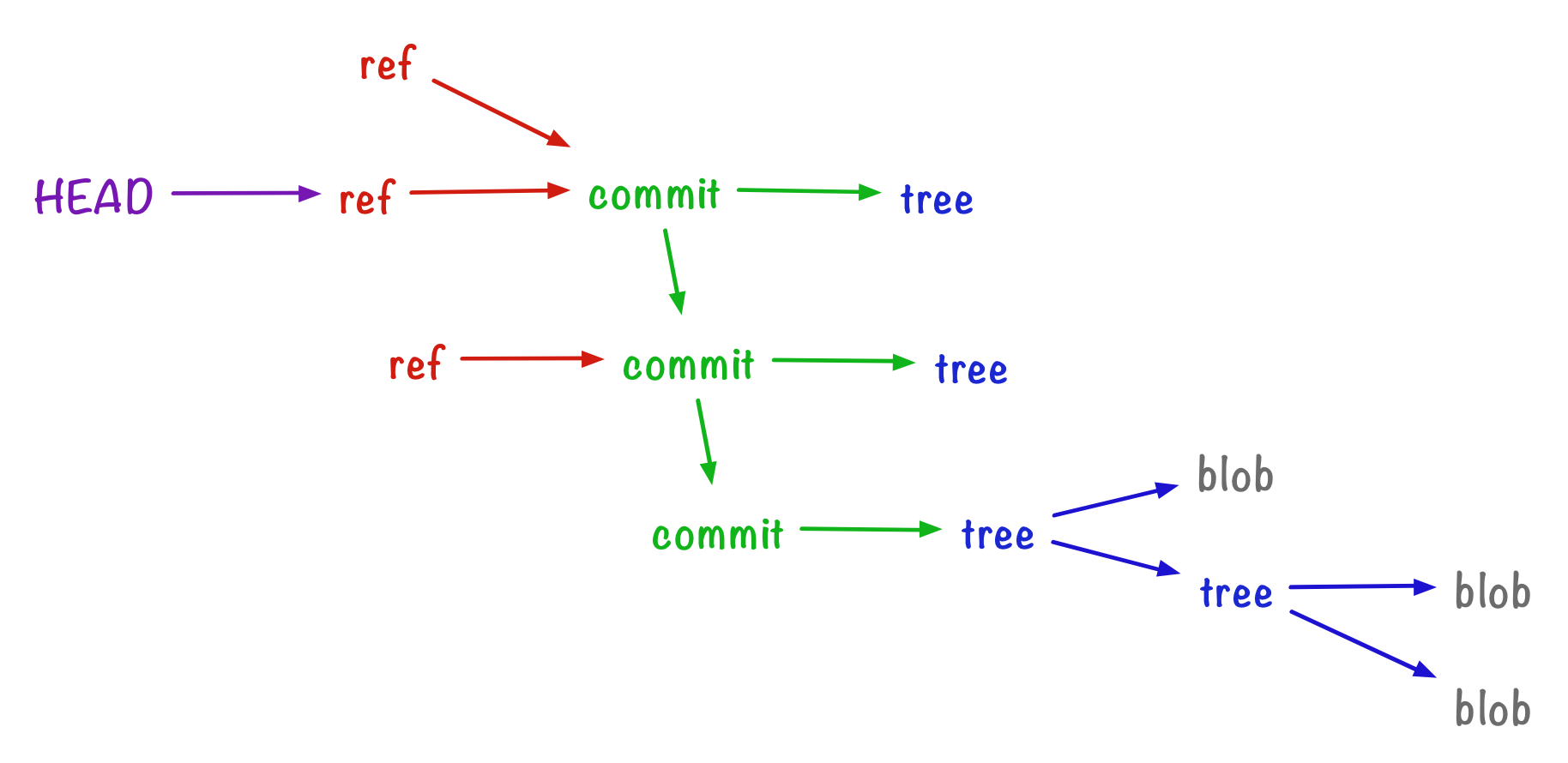
Git stores the contents of files as objects called blobs
Git stores snapshots of the filesystem hierarchy in objects called trees, which point to blobs (individual files) and other trees (subdirectories)
To build a sequential history and give context to snapshots, Git has objects called commits, which point to trees (the files and directories) and other commits (to build a history)
Branches and refs are human-readable labels to specific commits
Here’s a whiteboard sketch that shows how it all fits together:
Along the way, you’ve learnt the plumbing operations that manipulate these objects and pointers. This is everything that happens in a typical Git workflow:
git addis a combination of hash-object and update-index.git commitcomes from write-tree, commit-tree, and if you’re on a branch, update-refgit checkoutuses update-ref or symbolic-ref
I hope you now have a better understanding of How Git works under the hood, and it makes you a more confident and effective user when you return to the world of porcelain.
If you have any comments or feedback, please get in touch. I’d love to make the workshop even better for future readers.
Thanks for following along!