Digital preservation
Digital preservation is about protecting digital information to ensure it’s available for a long time into the future. Libraries and archives have old manuscripts and papers from centuries ago; digital preservation is about trying to give digital media a similar lifespan.
I’ve always been a digital packrat, saving fanfiction as a teenager when it became clear I couldn’t rely on my favourite websites to stay up.
I formalised those ideas when I went to work for Wellcome Collection and the Flickr Foundation, where I helped to build services to store digital collections.
Sub-topics:

Meeting my younger self
I reviewed 150,000 fragments of my online life, and I was reminded of the friends I found, the mistakes I made, and the growth I gained.

Hard problems in social media archiving
Preserving social media is easier said than done. What makes it so difficult for institutions to back up the Internet?
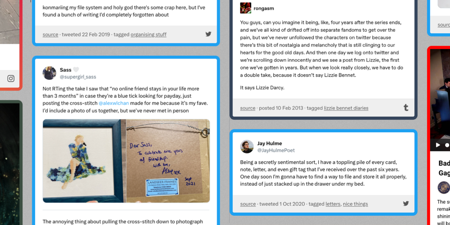
The Internet forgets, but I don’t want to
I don’t trust platforms to preserve my memories, so I built my own scrapbook of social media.

What I learnt about making websites by reading two thousand web pages
How to write thoughtful HTML, new-to-me features of CSS, and some quirks and relics I found while building my personal web archive.
Ignore AI upscaled YouTube videos with yt-dlp
Filter for formats that don’t include
-sr(“super resolution”) in their format ID.Creating a personal wrapper around yt-dlp
I’ve written a new script which calls yt-dlp with my preferred options, so I don’t have to copy my configuration across different projects.
Get the avatar URL for an Instagram page
Use
gallery-dl --get-urls "https://www.instagram.com/{page_name}/avatar".The “MCP” in Archivematica stands for “Master Control Program”
It’s nothing to do with generative AI.
Get the avatar URL for a Bluesky user
Make a request to the
app.bsky.actor.getProfileendpoint, passing their handle as theactorparameter.Looking up posts in the Bluesky API
Install the
atprotopackage, construct a client with your username/password, then call theget_post_threadmethod with yourat://URI.My favourite websites from my bookmark collection
Websites that change randomly, that mirror the real world, or even follow the moon and the sun, plus my all-time favourite website design.
Building a personal archive of the web, the slow way
How I built a web archive by hand, the tradeoffs between manual and automated archiving, and what I learnt about preserving the web.
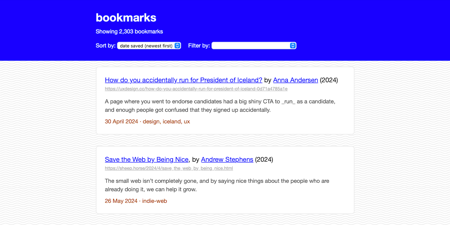
Creating a static website for all my bookmarks
To help me keep track of interesting links, I created a static website that keeps all my data locally. Why do I care about bookmarks, and how does my new site work?

What I’ve Learned by Building to Last
There are patterns in what lasts; people skills matter more than technical skills; long-lasting systems cannot grow forever.

How I create static websites for tiny archives
Start with a simple HTML file, then add features like templates, sorting, and filtering as they become useful.

Unexpected errors in the BagIt area
Exploring the many ways a BagIt bag can be invalid, and how you might want to build a process for validating bags to ensure the quality of your digital archive.

Using static websites for tiny archives
I’ve been creating small, hand-written websites to organise my files. It’s a lightweight, flexible approach that I hope will last a long time.
Downloading avatars from Tumblr
There’s an API endpoint that lets you download avatars in a variety of sizes.
Bitly will delete your account if you don’t use it for three years
Google will delete your account if you don’t use it for two years


The surprising utility of a Flickr URL parser
I made a library that knows how to read lots of different forms of Flickr.com URL, and I used
hyperlinkto do it.Preserving pixels in Paris
I went to France for a conference about archiving the web, and I came back with thoughts and photos.
Open a Safari webarchive from Twitter/X without being redirected
Disabling JavaScript when you open the webarchive file will prevent you from redirecting you to twitter.com.
Creating a Safari webarchive from the command line
We can use the
createWebArchiveDatamethod onWKWebViewto write a Swift script that creates Safari webarchive files.What’s inside a Safari webarchive?
The inside of a
.webarchivefile is a binary property list with the complete responses and some request metadata.Taking regular screenshots of my website
A screenshot a day keeps the bit rot at bay.
How to get a list of captures from the Wayback Machine
Use the CDX Server API to get a list of captures for a particular URL.
How to take a screenshot of a page in the Wayback Machine
Using Playwright to take screenshots and adding some custom styles gets a screenshot of a page without the Wayback Machine overlay.
My config for running youtube-dl
The flags and arguments I find useful when I’m using youtube-dl.
Going through my old school papers
Digitising and pruning my boxes of paper from school. In which I have nostalgia, sadness, and the sense that everything old is new again.
Saving your alt text from Twitter
Twitter’s archives don’t include the alt text you wrote on images, but you can save a copy with their API.


Replicating Wellcome Collection’s digital archive to Azure Blob Storage
How and why we keep copies of Wellcome’s digital collections in multiple cloud storage providers.
How to do parallel downloads with youtube-dl
Archive monocultures considered harmful
We are better off when the same topic is represented in multiple, different archives.
Downloading the AO3 fics that I’ve saved in Pinboard
A script that downloads the nicely formatted AO3 downloads for everything I’ve saved in Pinboard.
Storing multiple, human-readable versions of BagIt bags
How we use the fetch.txt file in a bag to track multiple copies of an object in our digital archive.
How I scan and organise my paperwork
My procedure for scanning paper, and organising the scanned PDFs with keyword tagging.
Saving a copy of a tweet by typing ;twurl
Digital preservation at Wellcome Collection
Slides from a presentation about our processes, practices, and tools.
Reversing a t.co URL to the original tweet
Twitter uses t.co to shorten links in tweets, so I wrote some Python to take a t.co URL and find the original tweet.
Getting a transcript of a talk from YouTube
Using the auto-generated captions from a YouTube video as a starting point for a complete transcript.
Finding the latest screenshot in macOS Mojave
A script for backing up Tumblr posts and likes
Since Tumblr users are going on a mass deletion spree (helped by the Tumblr staff), some scripts to save content before it’s too late.
Backing up full-page archives from Pinboard
A Rust utility for saving local copies of my full-page archives from Pinboard.
Backing up content from SoundCloud
Automatic Pinboard backups
A script for automatically backing up bookmarks from Pinboard