How I scan and organise my paperwork
I get a lot of documents as paper, which I scan and store as PDFs files. This lets me shred or recycle the originals (if I don’t need the physical copy), and minimise the space the paper takes up my office. I organise the PDFs in a Python app I wrote called docstore.
People have asked me how I do my scanning, so in this post I’m going to explain how I got to my current setup.
How do I scan paper?
I have a portable document scanner that I use to scan my paper. It’s a Canon ImageFORMULA P‑215:

When I want to scan a document, I separate the pages and place them face down in the scanner. It pulls in the pages one at a time, and scans both sides at once – I don’t have to feed it pages individually. If I’m scanning a long document, I can leave it unsupervised, and it works through the whole pile.
It connects to my Mac with a micro-USB cable. Newer scanners have Wi-Fi, which is especially useful if you use it with a laptop or mobile device – mine sits on my desk, so less of an issue for me.
I use the bundled scanning software, so I don’t need to install anything on my computer. The software is basic, but it does the job:

The software can recognise printed text, and it performs OCR on the scans. This means the PDF contains both an image and a transcription of the text, which I can search through later. (That said, I almost never use the transcripts, so I don’t know how accurate they are.)
I’ve been using this scanner for over six years, and it’s always worked reliably. I bought it for £225, and it looks like prices haven’t changed much – the portable scanner market isn’t a hotbed of innovation. When this unit fails, I’d be happy to replace it with whatever Canon’s current model is.
The quality of the scans isn’t amazing. In particular, the colour reproduction isn’t great, and the pages are sometimes shown at a skewed angle. It’s fine for home scans of black-and-white printed documents, but if you’re digitising photographs or archival material, it might not be such a great fit. This is for speed and convenience, not quality.
There are scanning apps for smartphones, but they depend on the quality of your camera, and you need to photograph each page individually. I’ve scanned nearly 25,000 pages with this scanner, and I wouldn’t want to try that with a phone.
If you want to do scanning in bulk, this sort of document scanner is a great investment.
How do I want to search my files?
Once I’ve used the scanner, I have a folder full of PDF files. For anything more than a few files, this gets messy – how do I organise them so I can find documents later?
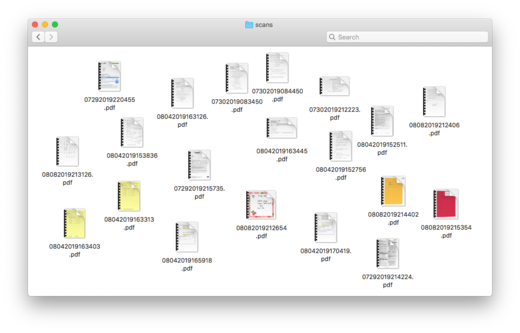
When I was designing docstore, it was useful to think about how I’d want to search my PDFs – if I’m building a system just for me, it should suit my use case! Here are some examples of questions I’ve had to ask recently:
Can I find a recent utility bill? This is often required as a proof of address.
Where was I living three years ago? When I’m applying to rent a flat, letting agents want to know where I’ve lived for the last three years. It’s easier to find the move-in papers and name of the estate agent, than try to recall from memory.
What were the results of my last eye test? When I go for an eye test, I take the results from my last test, so I can see how much my eyesight has changed.
Does ACME Corp have my new address? If I’ve moved house, and I can’t remember whether I’ve given a company my new address, I look at recent letters they’ve sent me, and which address they were sent to.
What are my travel plans for my next trip? When I travel, I like to have printed copies of my tickets and accommodation notes (even if they were originally sent by email). That means that even if my phone is stolen, lost, or out of battery in a strange place, I can still get around.
So typically I want to find documents within some loose categories, and then maybe narrow my search by date. With those searches in my mind, let’s thing about how I might organise the files.
How should I organise my files?
Most computers support organising files with directories (or folders). A directory is a collection of related files, and you can put directories inside other directories to create a hierarchy of files. This is analogous to managing physical pieces of paper: you put a page in a folder, a folder in a filing cabinet, the filing cabinet in an aisle, and so on.
This gives us a tree-like view of our files:
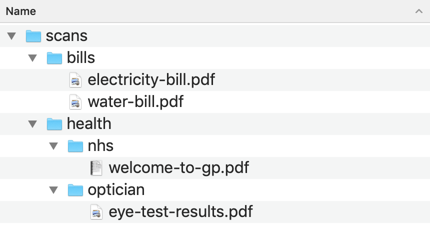
I’ve tried to sort my PDFs this way a couple of times, but it’s never stuck. I always run into the same issue: what’s the “right” set of folders to create?
Each file has one and exactly one place in a directory hierarchy. I have to pick a way to sort my files, and I can only make searches that fit that classification. I can’t make searches that span multiple directories.
An example: suppose I have an electricity bill. Do I put it in a folder called “home”, or “utility bills”, or a folder with the name of the provider? I might want to search for it later by any of those criteria, but I can only put it one directory. Or I could search for all three tags, which would return a smaller set and make it even easier to find.
So if I don’t want to use files and folders, what else can I try?
Something I’ve used in other organisation systems is keyword tagging, and that works much better for my brain. When I store something, I add a number of “tags” – one or more keywords that describe the document. Later, I can filter to find documents that have particular tags as a form of search.
I once heard tags described as a “search engine in reverse”, and it’s a nice image. I’m adding the keywords that I’ll likely use to search for something later. If I think I might look for something in three different ways, I can give it three different tags.
Consider the electricity bill again. Rather than putting it in a single folder, I could tag it with “home” and “utility bills” and “acme energy”, and I could find it later by searching for any one of those tags.
It helps that I have a good example of tagging to emulate: tagging in the world of fandom. On bookmarking sites like Pinboard and Delicious, fans have created intricate systems of tags to describe fanfiction, and by combining tags you can make very specific queries. There are shared conventions to describe word count, the fandom, the pairing, the trope, and many other things beside – which means you can even search bookmarks that were tagged by somebody else. For specific examples, I really recommend Maciej Cegłowski’s talk Fan is a Tool-Using Animal.
I use tagging in my Pinboard account (including for fanfic), so I’m quite used to it, and I know I like it. I decided to use tagging as the basis for my PDF organisation.
How did I create an app to tag my PDFs?
At a minimum, I want a PDF organiser that:
- Lets me store a file and give it some tags
- Shows me all the tags I’ve used
- Lets me find all the documents with a particular set of tags
This is similar to other tools I’ve built before – I’ve built lot of variants of an image organiser that uses tags. I chose to write it in Python, because that’s the language I’m most familiar with, and it let me get started quickly, but you could implement this idea in a lot of languages. (If I was starting fresh today, I’d be tempted to write it in Rust.)
I built the initial prototype with the responder web framework. That was a year ago, and I got the core features working in a few hours – then I’ve been adding polish and new features ever since.
I’ve recently switched to the more popular Flask, which is a great library for writing small web apps. (If you aren’t familiar with it, start with Miguel Grinberg’s Flask Mega-Tutorial.)
I have a bunch of libraries doing the heavy lifting, including:
- pdftocairo and ImageMagick to create thumbnails
- whitenoise for serving static files
- libmagic and mimetypes to detect the type of a file
- hyperlink for manipulating URL query parameters
The whole app is packaged in a Docker image, to make deployments easy. I can just as easily run it on my Linux web server as on my home Mac. If you have Docker installed, you can run it like so:
docker run \
--publish 8072:8072 \
--volume /path/to/documents:/documents \
greengloves/docstore:latestThis starts the web app running on http://localhost:8072, and any files you upload will be saved to /path/to/documents.
If you’d like to read the source code, it’s all available on GitHub.
How do you use docstore?
For simplicity, docstore only has a single screen. Here’s what it looks like, storing some of my ebooks:
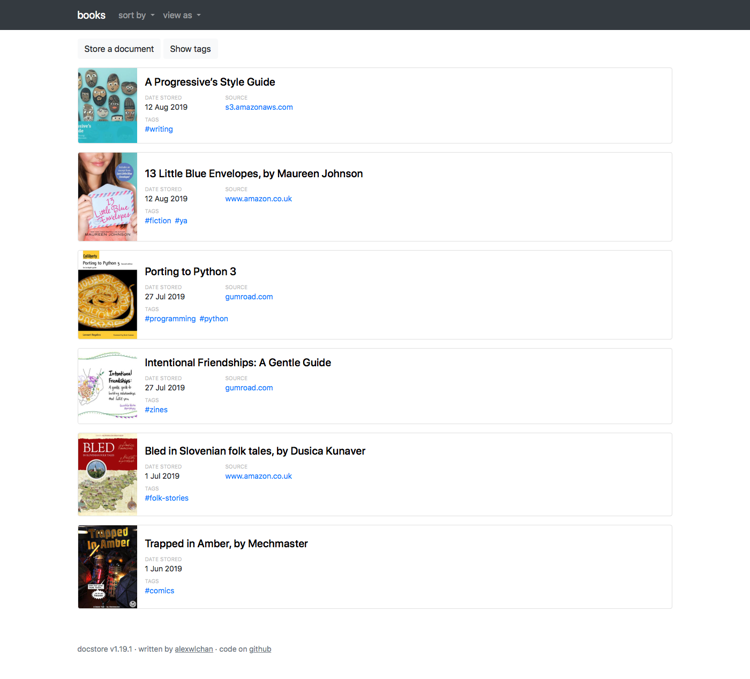
Most of the screen is taken up with a list of documents. Each document has a one-line description, a thumbnail, and some metadata.
The thumbnails make it easy to identify a document at a glance – book covers are particularly good for this, but it works in letters too. Companies tend to use consistent letterheads, so I learn to spot particular patterns as I’m scrolling a list.
The metadata includes the date I stored something (not necessarily the date of the document itself – I scanned a lot of stuff long before I saved it in docstore), and a list of tags. If I click one of the tags, it filters the documents to ones that have that tag. Tags stack, so if I click “programming” and then “programming:python”, I’ll only see documents that have both of those tags.
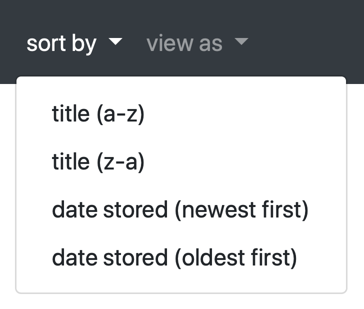
In the navbar, there are options to sort by title or by date:
The “Store document” button opens the form for adding a new files. It’s a standard web form:
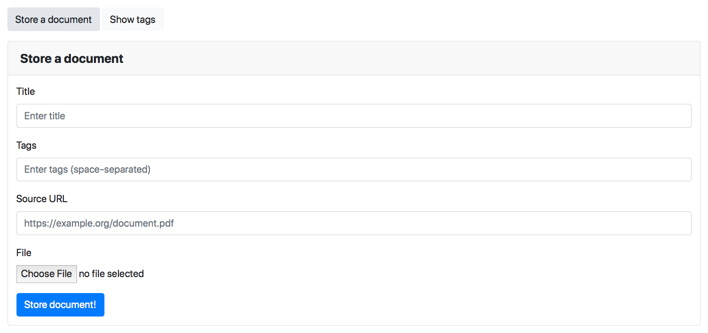
Although I originally built this to handle scanned PDFs, I get a lot of correspondence electronically – for example, I get my bank statements from an online portal, not in the post. I want to keep all those documents alongside my scanned papers, so I store them in docstore too, and the source URL lets me track where I downloaded a file from.
The “Show tags” button shows a list of tags in the current view. Clicking any one of the tags will filter the documents to ones that have that tag:
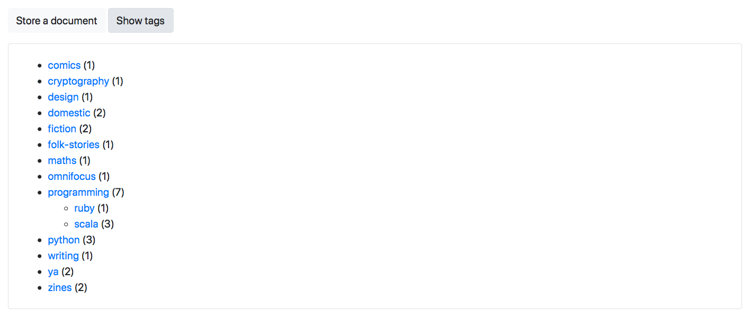
This list is context-dependent: if I’ve already applied a tag query, it shows me the list of tags for documents that match my query. For example, if I selected the “programming” tag, I’d only see the tags used by files that are tagged with “programming”.
What’s my current scanning procedure?
When I get a piece of paper, this is what I do with it:
- I scan it with my document scanner, and get a PDF
- I upload the PDF to docstore, adding some appropriate tags
- If the page has sensitive information, like my bank details, I shred it. If it’s not sensitive, say marketing material, it goes in the paper recycling.
I try to scan everything the day it arrives, so I don’t build up a backlog.
I use semi-structured tags, with a common prefix to group similar tags. Here are some examples of what my tags look like:
bank:credit-card-4567car:austin-WLG142Ehealth:opticianhome:667-dark-avenuepayslipsproviders:acme-energytravelutilities:water
I run several instances of docstore, each one for a different type of document:
- Home correspondence. Letters, bills, insurance documents, that sort of thing.
- Manuals and reference documents. Whenever I get a new appliance, I download the manual from the manufacturer website. Docstore makes it easy to find, and then I can use full-text search on the PDF to answer specific questions.
- Old schoolwork. I haven’t looked at some of my school books in over a decade, so I recently scanned them all and recycled the paper. I kept a small number of representative books as mementos, but I didn’t need four boxes worth.
- Work documents. I run an instance on my work laptop, so I can manage any documents I need for work in the same way – but the files never have to leave the corporate network.
At time of writing, I’ve got 1585 PDFs with 23,795 pages, and most of the original paper has been recycled. It’s a big saving!
How can you do this yourself?
Buy a document scanner, decide how you want to organise, start scanning!
If you want to buy a document scanner, I like my Canon ImageFORMULA and I’d be happy to buy another from the same line. I also trust recommendations from Wirecutter, who discuss the topic in more detail.
It’s worth thinking about how you’ll organise your scans before you start scanning your existing paper – whether you use keyword tagging like me, some files and folders, or something else. Depending on what you decide, it might be much easier to organise as you go along, rather than build up a big backlog, so sort that out early!
If you want to run docstore yourself, the code and deployment instructions are all on GitHub: https://github.com/alexwlchan/docstore
Interesting links
If you enjoyed this post, you might also want to read:
Designing better file organization around tags, not hierarchies, by Nayuki. This is a detailed essay about a design for a filesystem that’s based entirely around keyword tagging, not hierarchies. This essay informed some of the internal design decisions in docstore.
Fan is a Tool-Using Animal (video, transcript), by Maciej Cegłowski. This is a talk about the use of tagging and similar systems in fannish circles.
Situated Software, by David MacIver. Although I didn’t mention the term above, docstore feels like a good example of situated software.