Beware of incomplete PDF redactions
A while back I was reviewing some legal documents. As part of my review, I was checking that everything was suitable to be made public.
Black boxes had been added to redact certain sections, to prevent leaking personal information like signatures and addresses:

I received the documents as a set of PDFs, and as I was reading them, something felt off about the black boxes. It’s hard to explain, but I got a spidey sense that the boxes were somehow separate from the rest of the document. As I dragged to select text, the boxes weren’t being selected.
If the boxes were separate – could they be removed?
If they were removed – would you see the redacted information?
Obviously, I had to check.
I know you can pull apart PDF documents with advanced PDF editors like Adobe Acrobat Pro, but I don’t know how to use any of those programs. I did download a free trial and play around, but I didn’t get anywhere useful.
I also know you can manipulate PDFs in Python, which I’ve done a couple of times before. I found a blog post with some Python for extracting all the images from a PDF, which I adapted into my own script. I ran my script over the legal documents, and to my horror, it produced a bunch of images that should have been redacted. And if I could do it, so could somebody else.
Oops.
The person who’d sent me the documents had tried to redact the information, and to them it looked like they’d succeeded. What went wrong?
The problem is that PDF is a complicated format, and getting redaction right is tricky.
PDF documents can be made up of multiple layers, and when you view the document those layers get flattened into a single page. Imagine the layers are stacked vertically, and you’re looking down at them from above. In this case, there were two layers: an image layer with the original document, and a transparent layer with a black rectangle over the area that was meant to be redacted:
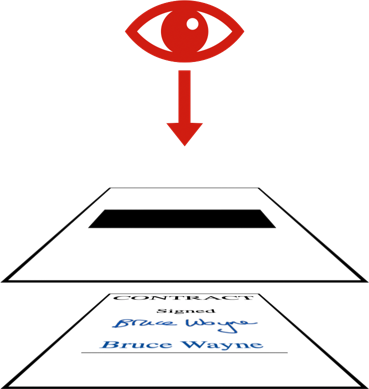
Although it looked as if the personal information had been removed, you could still get it by inspecting the individual layers. The information wasn’t really gone, just hidden.
If you want to redact information in a PDF safely, you need to remove it from all the layers. This means that even if somebody picks apart the document, they can’t find what you’ve removed:
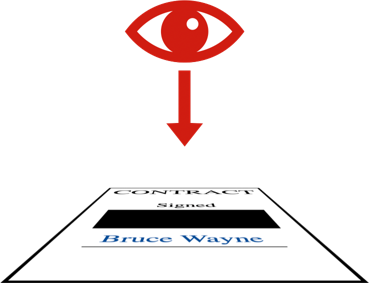
The problem is, a PDF with and without layers look near identical. There was a difference in my PDF viewer which tipped me off to the issue, but it’s so subtle I don’t know how to explain it.
I’d love to tell you how to redact PDFs; a set of steps that guarantee information security. Unfortunately I don’t redact PDFs very often, and I don’t know how to do it safely – looking at the layers is one way to get around redaction, but maybe there’s another I’m not aware of.
Instead, take this as a cautionary tale. PDFs are fiddly, and it’s easy to have something that looks redacted but actually isn’t. If you’re not sure how to do it, get somebody more experienced to check your work – don’t just draw a rectangle and call it a day.