How we do bulk analysis of our Prismic content
At work, we use Prismic as a headless CMS for our public website. If you see images or text that aren’t part of the catalogue, they’re probably managed through Prismic.
To help us manage our growing Prismic library, we’ve built a number of tools and scripts to analyse our content in bulk. This includes:
- measuring the use of different slices
- finding examples of interesting documents
- running linting and validation rules
All our scripts and code are open source and publicly available, and in this post I want to give a quick tour of the key ideas.
My examples all use Prismic’s JavaScript library, but most of these ideas aren’t Prismic-specific – you could apply them to other CMSes.
Download all our Prismic content
The first thing we need to do is download all our Prismic content.
You can export a snapshot in the “Import/Export” tab of the Prismic GUI, but that’s not what we use for bulk analysis – we wanted something that could run synchronously, and be triggered programatically.
Fortunately, the Prismic client library includes a dangerouslyGetAll() method, which downloads all your documents. It includes both pagination and throttling, so it can fetch everything without overwhelming the Prismic API. We can put this in a short script:
// npm i node-fetch @prismicio/client
// node download-documents-1.js
const fetch = import('node-fetch'); // ^3.3.0
const prismic = require('@prismicio/client'); // ^6.7.1
/** Returns an array of all the documents in a Prismic repository. */
async function downloadDocuments() {
const endpoint = prismic.getEndpoint('wellcomecollection');
const client = prismic.createClient(endpoint, { fetch });
const documents = await client.dangerouslyGetAll();
return documents;
}
downloadDocuments()
.then(documents => console.log(documents));This can be somewhat slow – our library has about 3.5k documents, and it takes 20 seconds to download. Over time, as we write more and bigger documents, that’s only going to get slower.
To speed things up, we save our snapshot to a JSON file, and we use refs to skip unnecessary downloads. Prismic uses refs as identifiers for different versions of content – whenever you make a change, you get a new ref. By including the ref in the filename, we can tell if we’ve already saved this version of the content – and we can skip downloading it again.
// npm i node-fetch @prismicio/client
// node download-documents-2.js
const fs = require('fs');
const fetch = import('node-fetch'); // ^3.3.0
const prismic = require('@prismicio/client'); // ^6.7.1
/** Downloads all the documents in a Prismic repository, saves them to
* a JSON file, and returns the name of the file. */
async function downloadSnapshot() {
const endpoint = prismic.getEndpoint('wellcomecollection');
const client = prismic.createClient(endpoint, { fetch });
const masterRef = await client.getMasterRef();
const snapshotFile = `snapshot.${masterRef.ref}.json`;
if (!fs.existsSync(snapshotFile)) {
const documents = await client.dangerouslyGetAll();
fs.writeFileSync(snapshotFile, JSON.stringify(documents));
}
return snapshotFile;
}
downloadSnapshot()
.then(snapshotFile => console.log(`Saved snapshot to ${snapshotFile}`));We can retrieve the documents by reading the snapshot:
// node read-documents.js
const fs = require('fs');
function readJson(path) {
const jsonString = fs.readFileSync(path).toString();
return JSON.parse(jsonString);
}
const documents = readJson('snapshot.Y5dUDREAAF9hpGNe.json');
console.log(`There are ${documents.length} documents in Prismic`);Splitting the download and the analysis is a classic pattern in data pipelines. The initial download is slow, but the subsequent processing is much faster.
Now we have this snapshot, what can we do with it?
Use case #1: Find (and test) all our content pages
One thing a snapshot can do is give us a link to every bit of content we have in Prismic:
const nonVisibleTypes = new Set([
'audiences', 'interpretation-types', 'labels', 'teams',
]);
function createUrl(baseUrl, type, id): string {
switch (type) {
case 'webcomics':
return `${baseUrl}/articles/${id}`;
default:
return `${baseUrl}/${type}/${id}`;
}
}
for (let doc of documents) {
if (!nonVisibleTypes.has(doc.type)) {
console.log(createUrl('http://localhost:3000', doc.type, doc.id));
}
}
// http://localhost:3000/events/Xagh1RAAACMAozgg
// http://localhost:3000/articles/Ye6WHxAAACMAXTxz
// http://localhost:3000/books/YW7dSREAACAANjZnI’ve found this useful when doing a big, disruptive refactor – it takes a while, but I can use this list to grind through every page. I fetch every page from a local copy of the site, check for errors, and then I can fix them before they’re deployed to prod.
We get alerts for errors on the public site, and now we test a sample of URLs as part of deployment – and testing everything helped find the “interesting” examples that went into that sample.
Use case #2: Counting our slices
Within Prismic, slices are the building blocks of a page. You can define your own slice types and how they’re rendered on your site, and each slice can have different data and structure. Content editors can assemble a sequence of different slices in the GUI editor to create a page.
To help us manage our slice types, we made a tool that counts how many times each slice type is used. It goes through every page in the snapshot, counts all the slices it uses, then prints the result:
for (let doc of documents) {
if (doc.data.body) {
for (let slice of doc.data.body) {
sliceTally[slice.slice_type] = (sliceTally[slice.slice_type] || 0) + 1;
}
}
}
Object.entries(sliceTally)
.sort((a, b) => a[1] - b[1])
.forEach(entry =>
console.log(`${entry[1].toString().padStart(6, ' ')}\t${entry[0]}`)
);The output is a simple table:
$ node tally-slices.js
2 map
15 imageList
22 youtubeVideoEmbed
53 quote
969 textWe use this tally to answer questions like:
Which slice types are most used? If we’re doing optimisation work, it makes more sense to focus on a heavily used slice, where any improvements have a bigger impact.
Which slice types are least used? Are there any slice types which are never used? This might start a conversation about why that slice type isn’t being used – maybe it’s unnecessary, or it needs some tweaking.
If we’ve deprecated one slice type and replaced it with another, have we migrated all the old uses? Can we safely delete the old slice type?
This sort of slice analysis was the initial motivation for downloading Prismic snapshots, but once we had the framework in place we found other uses.
Use case #3: finding interesting examples
In the example above, we saw that there are only two examples of the “map” slice. If I was doing some work on the map code, it might be useful to know which pages have a map, so I can test my changes with a working example.
We can find this with just a small change to the previous script:
for (let doc of documents) {
if (doc.data.body) {
if (doc.data.body.some(slice => slice.type === 'map')) {
console.log(`${doc.id} has a map slice`);
break;
}
}
}We also use this when we update our slice types. Over time, we’ve deprecated slice types as we recognise their flaws, and replaced them with newer types. We then try to migrate all the old slices into the new type, and this script helps us find them.
Some of this is possible with the Prismic API, but what I like about this approach is that I can write incredibly flexible queries. And what if we didn’t want to find just one example, but every example?
Use case #4: running validation rules
Prismic itself doesn’t have any sort of validation logic in the editor, and that’s a deliberate choice. They’ve thought carefully about it and decided not to do it, which is a shame because there are certain places where it would be really useful – but this snapshot mechanism allows us to build our own validation tools.
As we loop through the documents, we can apply logic that looks for documents which have issues. For example, in our event model, we can link to interpretation types (audio described, closed captioning, sign language interpreted, and so on). When the interpretation types get reorganised or restructured, that can break the links on old events – but we can detect them in a snapshot:
function detectBrokenInterpretationTypeLinks(doc) {
if (doc.type === 'events') {
const brokenLinks = doc.data.interpretations.filter(
it => it.interpretationType.type === 'broken_type'
);
if (brokenLinks.length > 0) {
console.log(
`Event ${doc.id} has a broken link to an interpretation type; remove or update the link.`,
);
}
}
}
for (let doc of documents) {
detectBrokenInterpretationTypeLinks(doc);
}We’ve used this to detect and fix several issues on the site, including:
- broken links in contributor bios
- Outlook “safelinks” that have been copied out of an email
- colour choices that needed updating after a palette refresh
Some of these are rules we run all the time; others are rules we ran as a one-off for specific tasks.
To make these issues more visible to our content team, we’ve set up a dashboard that reports on any errors. The link takes them directly to the affected document in the Prismic web editor, so they can fix issues as quickly as possible:
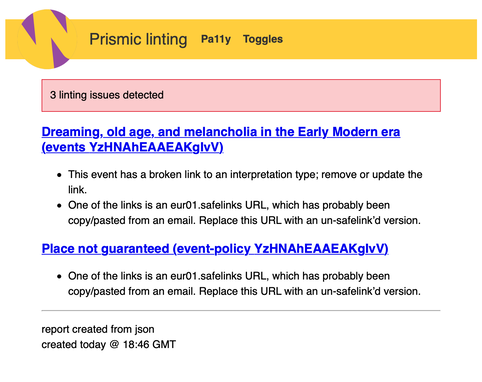
The dashboard updates on a fixed schedule, so new errors will appear as they’re found, and disappear as they’re fixed. It’s already helped us fix dozens of errors.
Over time I’m sure we’ll add more rules and checks, and each one is a small extension on top of the system we’ve already built. That’s how we made a lot of this Prismic tooling – as an iteration on something that came before.
And so on
I have more ideas about how we might use this.
For example, all the uses cases above have treated pages as individual entities, but these pages have relationships with each other. I think we could do something interesting by considering our Prismic library as a whole, and working out how all the pages on the site link together. Are we consistent in the way we tag and organise pages? Do we create the proper breadcrumb trails for hierarchical content? And so on.
You can find all our Prismic scripts on GitHub, which are more full-featured than the code above – but I hope my examples give you the general idea.