Spotting spam in our CloudFront logs
About two months ago, I wrote about some Python code I’d written to parse CloudFront logs. I wrote this code to help with analysing some searches on wellcomecollection.org, and I thought it would be useful to explain a bit more of what I was doing.
There’s a lot of spam in the catalogue search. Somebody types in a search query which can’t possibly return any results – instead it’s a message (often not in English) promoting sketchy-sounding services and domains. Call me sceptical, but I don’t think somebody who types in:
escort girls in your area play free casino games ✔️ with chatgpt ⏩ whatsapp scamalot.xyzis actually looking for catalogue results in a library/museum website.
I don’t know why people set up bots to do this – but whatever the reason, dealing with this sort of spam is an inevitable part of running a website on the public Internet.
Before I started this work, we were sending all these spam queries to our back-end search API and Elasticsearch cluster. Over time, the load from the spam was starting to add up, and starting to crowd out real queries on our cluster.
We wanted to find a way to identify the spam, so we could return a “no results page” ASAP, without actually sending the query to our Elasticsearch cluster. It was usually “obvious” if you read the queries as a human, but how could we teach the computer to make the same distinction?
I started by using the code from my last post to get all the CloudFront logs for our catalogue search:
import datetime
import json
class DatetimeEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime.datetime):
return obj.isoformat()
log_entries = get_cloudfront_logs_from_s3(
sess,
Bucket="wellcomecollection-experience-cloudfront-logs",
Prefix="wellcomecollection.org/prod/"
)
with open("search_log_entries.json", "w") as out_file:
for entry in log_entries:
if entry["cs-uri-stem"].startswith("/search"):
out_file.write(json.dumps(entry, cls=DatetimeEncoder) + "\n")That gave me about 7 million log entries that I could analyse. Then I started developing my spam heuristic, which had a single Python function as its interface:
def is_spam(log_entry) -> bool:
return FalseTo develop the heuristic, I wrote a bunch of versions of this function, trying various techniques to look at different fields in the log entry and decide if a particular request was spam. To help me evaluate the different versions, I wrote a test script I could run repeatedly as I tweaked the function:
import random
import time
import humanize
import termcolor
spam = []
legit = []
# Get all the log entries
#
# This will load them into a single list, which uses a lot of memory.
# It is possible to do this in a more memory-efficient way using a
# generator, but I had memory to spare.
log_entries = [json.loads(line) for line in open("log_entries.json")]
# Go through all the log entries and classify them as spam/not spam
time_start = time.time()
for log_entry in log_entries:
if is_spam(log_entry):
spam.append(log_entry)
else:
legit.append(log_entry)
time_end = time.time()
# Print a brief summary of the results
print(f"Rejected = {humanize.intcomma(len(spam))}")
print(f"Allowed = {humanize.intcomma(len(legit))}")
print(f" = {len(spam) / (len(spam) + len(legit)) * 100:.2f}% marked as spam")
elapsed = time_end - time_start
print(f"Per req = ~{elapsed / len(queries)}s")
# Print a sample of the log entries marked as spam/not spam, to give
# me something to evaluate.
print("---")
for log_entry in random.sample(spam, k=min(100, len(spam))):
print(termcolor.colored(log_entry["cs-uri-query"], "red"))
print("---")
for log_entry in random.sample(legit, k=100):
print(termcolor.colored(log_entry["cs-uri-query"], "green"))The output gives me a summary with a few statistics:
Rejected = 5,136,696
Allowed = 1,805,073
= 74.00% marked as spam
Per req = ~1.4436019812105793e-05sThe proportion of rejected traffic is so I can see whether my proposed heuristic is actually making a difference to the volume of requests. The per request time is for measuring performance; I didn’t want to introduce noticeable latency for legitimate users.
It also prints a random sample of the queries marked as legitimate and spam. This gave me a spot check on the heuristic – I could see if legitimate queries were being rejected, or if I wanted to add another rule for matching spam.
Repeatedly re-running this test harness gave me a workflow for developing my spam detection heuristic: I’d tweak my function, re-run, and see how it affected the results. I kept iterating until I was catching a decent proportion of spam, without penalising real users.
Most of my analysis focused on the search query, and there were several patterns I spotted which seemed to be strong indicators of spam:
Certain keywords like
chatgpt,casinoandcrypto.This was my first idea, because it was pretty obvious in the queries I was reading, but it was dropped from the final heuristic for two reasons. It only dropped a fairly small amount of traffic (~2%) and it was hard to agree on a list of words that were definitely spam.
Emoji, of which ⏩, ✔️, ㊙️ were particularly common examples. There’s no emoji in our catalogue data so it’s unlikely a real person would search for it (and they won’t find anything if they do!).
Long, all-Chinese queries. There is some Chinese in the catalogue, but it’s a tiny proportion – the vast majority of our data is in English.
Mangled character encodings, aka Mojibake. Not all of the non-English text was encoded properly, and there were a lot of queries like
â\x8f©â\x9c\x94ï\x8fã\x8a. I don’t think a real person would ever type this in, but a poorly coded spam bot quite likely.
As I was going, I did tally some other fields in the logs I’d marked as spam, to see if I could spot any other patterns I could use for spam detection – for example, I counted IP addresses to see if all the spam was coming from a single IP address that we could just block.
import collections
spam_ips = collections.Counter(log_entry["c-ip"] for log_entry in spam)Unfortunately I didn’t find any good patterns this way, so I stuck to the query-based analysis.
For the first version of our spam detection, I settled on this heuristic:
Reject queries with more than 25 characters from character ranges which are rarely used in our catalogue data (Chinese, Korean, Mojibake, emoji)
Later we reduced that threshold to 20, and so far it seems to have worked well. You can see the implementation and the associated tests on GitHub.
If your query is marked as spam, we now show the “no results” page immediately in our frontend web app, rather than sending your search to our backend Elasticsearch cluster. As part of this change, we tweaked the copy on our “no results” page, asking people to email us if their search unexpectedly returned no results:
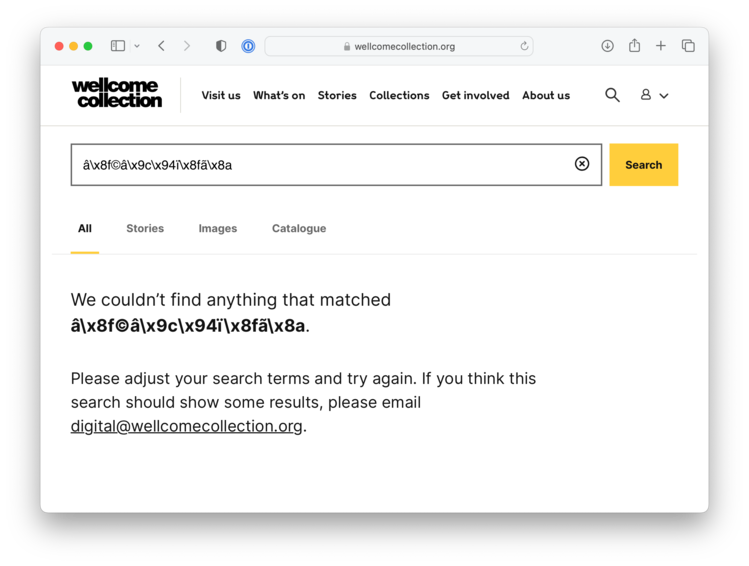
This was a hedge against mistakes in the spam heuristic – if it somehow got a false positive and binned a query from a real user who should have seen results, we’d hear about it. In practice, I don’t think there’s been a single one. We’ve managed to cut the load on our Elasticsearch cluster, without impacting real users.
I’m almost certain our spam is automated bots rather than targeted spam, which is why I can safely publish this analysis. Nobody is going to read this and adapt their spam attack to counter it, but maybe it’ll be useful if you have to analyse a spam problem of your own.