Part 3: Context from commits
If you’ve got this far, you should have finished part 1 and part 2 – if not, return to those first.
In the first two parts, we saw how to use trees to take a snapshot of an entire repository – but we don’t know why particular trees are significant. Why was this an interesting snapshot of the repo? We want to add context to our trees – enter commits.
Giving context to a single tree
We can create a commit from a tree with the commit-tree command:
$ echo "initial commit" | git commit-tree 11e2f923d36175b185cfa9dcc34ea068dc2a363c
65b080f1fe43e6e39b72dd79bda4953f7213658bWe pass a message and the ID of a tree, and we get back another object ID – like everything else, commits are objects!
We can inspect its type:
$ git cat-file -t 65b080f1fe43e6e39b72dd79bda4953f7213658b
commitWe can see it in the Git object store:
$ find .git/objects -type f
.git/objects/11/e2f923d36175b185cfa9dcc34ea068dc2a363c
.git/objects/65/b080f1fe43e6e39b72dd79bda4953f7213658b
.git/objects/89/72388aa2e995eb4fa0247ccc4e69144f7175b9
.git/objects/99/68b7362a7c97e237c74276d65b68ca20e03c47
.git/objects/a3/7f3f668f09c61b7c12e857328f587c311e5d1d
.git/objects/b1/3311e04762c322493e8562e6ce145a899ce570
.git/objects/cb/68066907dd99eb75642bdbd449e1647cc78928
.git/objects/ce/289881a996b911f167be82c87cbfa5c6560653
.git/objects/dc/6b8ea09fb7573a335c5fb953b49b85bb6ca985And we can pretty-print its contents:
$ git cat-file -p 65b080f1fe43e6e39b72dd79bda4953f7213658b
tree 11e2f923d36175b185cfa9dcc34ea068dc2a363c
author Alex Chan <alex@alexwlchan.net> 1520806168 +0000
committer Alex Chan <alex@alexwlchan.net> 1520806168 +0000
initial commitThe first line is a pointer to the tree.
The second and third lines give some information about the author and committer – their name, email address, and a Unix timestamp. The author is the person who wrote a patch, while the committer is the person who checks that patch into the codebase. Usually they’re the same person, but they can differ (especially on large projects like the Linux kernel) – so there are separate fields.
Finally, the rest of the commit is the free text message – usually called a commit message. This allows us to include any other details that might explain the significance of this snapshot.
This commit has far more context than our original tree: it tells us when it was created, who by, and the free text message lets us include any other relevant details.
Building a linear history
Once we have a single commit, the next thing to do is build a sequence of commits. A series of snapshots at different times, which track the history of our code. We can add a “-p” flag to commit-tree, which points to a parent commit.
Let’s go ahead and make some changes, then create a second commit.
$ git update-index --add c_creatures.txt
$ git write-tree
f999222f82d1ffe7233a8d86d72f27d5b92478ac
$ echo "Adding c_creatures.txt" | git commit-tree f999222f82d1ffe7233a8d86d72f27d5b92478ac -p 65b080f1fe43e6e39b72dd79bda4953f7213658b
fd9274dbef2276ba8dc501be85a48fbfe6fc3e31Let’s inspect this new commit:
$ git cat-file -p fd9274dbef2276ba8dc501be85a48fbfe6fc3e31
tree f999222f82d1ffe7233a8d86d72f27d5b92478ac
parent 65b080f1fe43e6e39b72dd79bda4953f7213658b
author Alex Chan <alex@alexwlchan.net> 1520806875 +0000
committer Alex Chan <alex@alexwlchan.net> 1520806875 +0000
Adding c_creatures.txtThis is similar to before, but we have a new line: “parent”, which refers to the ID of the previous commit.
Starting from here, we can work backwards to build a history of the repository. The porcelain command log lets us see that history:
$ git log fd9274dbef2276ba8dc501be85a48fbfe6fc3e31
commit fd9274dbef2276ba8dc501be85a48fbfe6fc3e31
Author: Alex Chan <alex@alexwlchan.net>
Date: Sun Mar 11 22:21:15 2018 +0000
Adding c_creatures.txt
commit 65b080f1fe43e6e39b72dd79bda4953f7213658b
Author: Alex Chan <alex@alexwlchan.net>
Date: Sun Mar 11 22:09:28 2018 +0000
initial commitLet’s briefly recap: we started with blobs, which contained the contents of a file. Then trees let us hold filenames and directory structure, by referring to blobs and other trees – and thus take snapshots of the state of a repo. Now we have commits, which refer to trees and give them context. Commits can refer to parent commits, which allows us to construct a history.
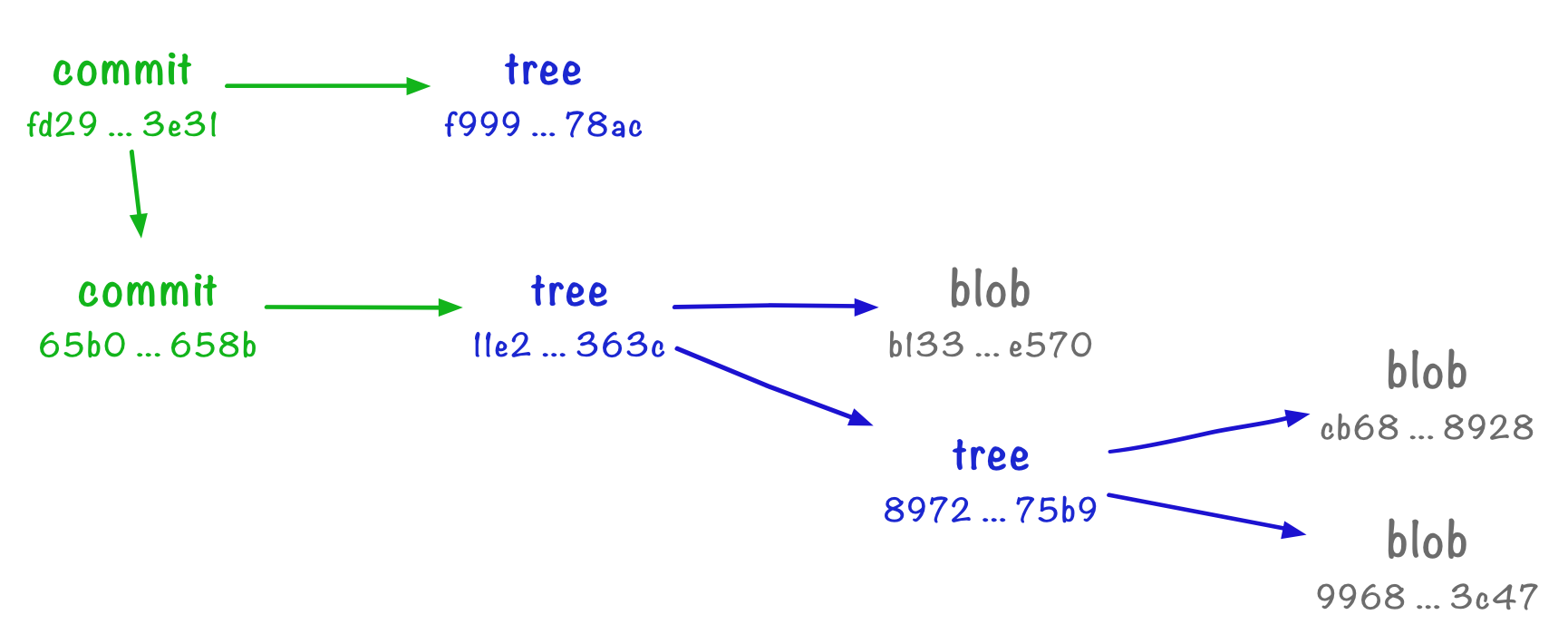
This is looking pretty close to a typical Git workflow! Let’s try some exercises.
Exercises
- Take one of the trees you created in part 2, and create a commit object.
- List all the files in
.git/objects, and check you can see your new commit. Inspect the object you’ve just created. - Make an edit to one of your files, create a new tree, then create another commit from that tree, using the original commit as its parent.
Repeat step 3 a couple of itmes. Create several commits that form a linear history – each has the previous commit as its parent.
- Use a porcelain
git logto see the history you've just created. - You can create a commit with more than one parent, by supplying the
-pflag more than once. Try creating a few commits with multiple parents. This is called a merge commit.
Useful commands
echo "<commit message>" | git commit-tree <tree ID>echo "<commit message>" | git commit-tree <tree ID> -p <commit ID>git log <commit ID>Notes
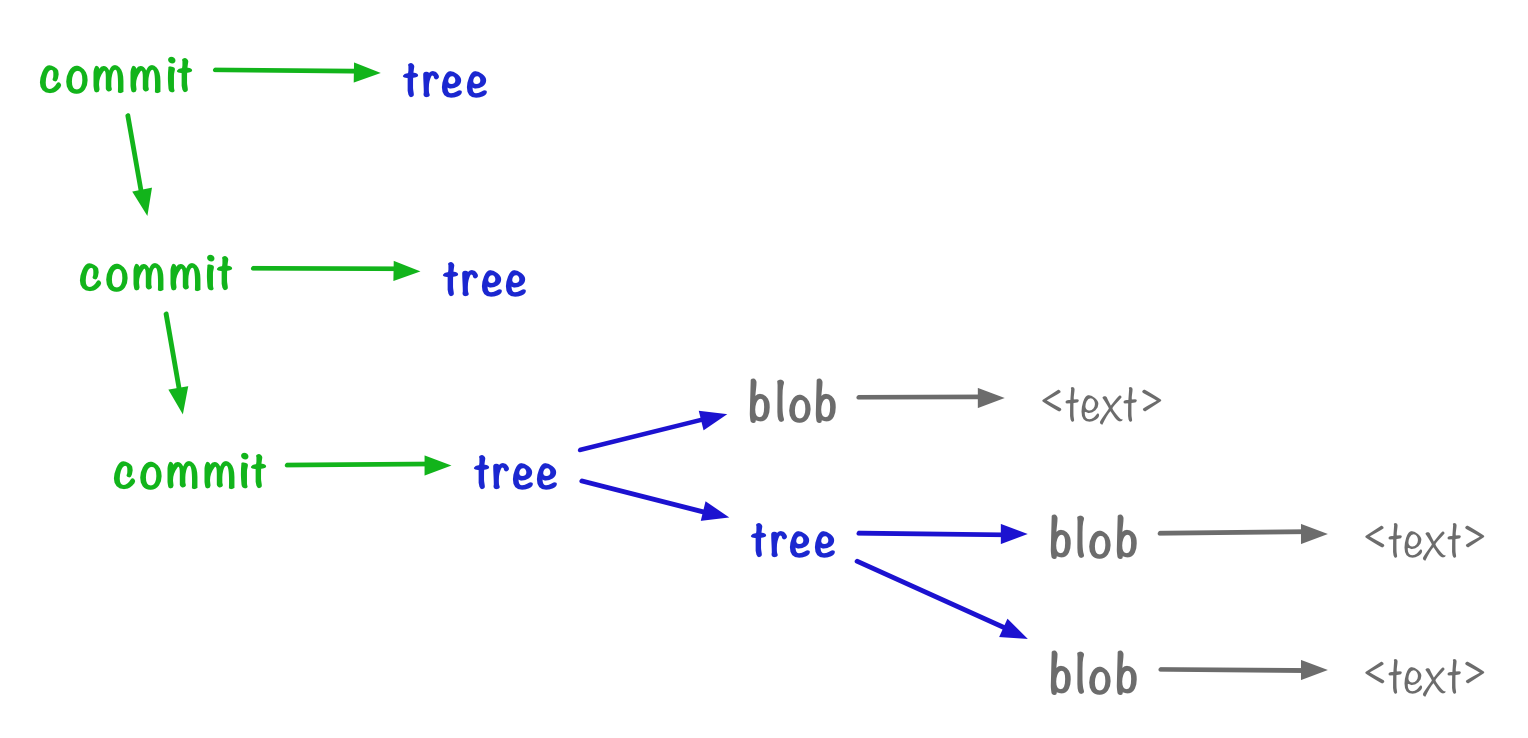
Now we’ve seen the three main types of object in Git:
- Blobs, which store the contents of a file
- Trees, which point to blobs and trees, and record the filenames and layout of our directories
- Commits, which give point to trees and commits – to give context to an individual tree, and to construct a sequential history
We can update our diagram:
So now we can reconstruct the state of repo at any point in history, and we have the context to know why those points are significant. But if we want to talk about commits, we need to pass around commit IDs – which are SHA1 hashes. These are quite unwieldy!
In the final part of this workshop, we’ll look at creating references for a more human-friendly way to talk about our commits.