A Python function to iterate through an S3 Bucket Inventory
For a couple of our S3 buckets at work, we use S3 Bucket Inventory to track their contents. Once a week, it creates an inventory; a collection of compressed CSV files that describe every object in the bucket. If we want to analyse everything in the bucket, reading this inventory can be cheaper and faster than making thousands of List calls with the S3 API. The data may be a few days old, but that’s a reasonable tradeoff.
When you get a new inventory, you get a manifest file which points to the individual inventory files, plus some metadata and CSV schema.
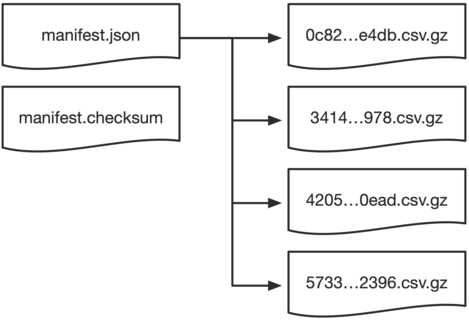
(The inventory files don’t contain the objects in any sort of obvious order; each file contains a seemingly random subset of the bucket. I wonder if this is giving us any sort of clue about S3’s inner workings? Maybe the inventory files reflect an internal sharding scheme?)
Several times now, I’ve written a Python function to traverse this structure – you give it the location of the manifest file, then it goes and pulls records from the individual inventory files. It allows me to iterate through the contents of the bucket in a similar way to using a List API:
from pprint import pprint
sess = boto3.Session()
for s3_obj in list_bucket_inventory_contents(
sess,
bucket="inventory-destination-bucket",
manifest_key="ReplicaPrimaryWeekly/2023-02-05T01-00Z/manifest.json",
):
pprint(s3_obj)which gives a generator of Python objects like:
{'Bucket': 'wellcomecollection-storage-staging',
'ETag': '0eb219d63a49891825d5f73a0062158a',
'IsDeleteMarker': False,
'IsLatest': True,
'Key': 'digitised/b10109377/v1/data/objects/b1000290x_hin-wel-all-00000026_0010.jp2',
'LastModifiedDate': datetime.datetime(2019, 12, 4, 18, 6, 28),
'Size': 1849074,
'StorageClass': 'STANDARD_IA'}There are almost certainly more efficient ways to do some of my processing if we were using a columnar format like Apache Parquet, but our inventory is small enough that this is still manageable – we have millions of objects, not billions. I’m already familiar with Python, and this wrapper means I can write my analysis scripts very quickly – if they then take a while to run in the background, that’s not an issue.
It’s not a complicated function, just a bit fiddly. To save me writing it from scratch again, I’ve saved it below, so I can just copy/paste it into my next project. If it’d be helpful to you, feel free to do the same.
import datetime
import csv
import gzip
import json
import boto3
def list_bucket_inventory_contents(sess, *, bucket, manifest_key):
"""
Iterate through the contents of an S3 Bucket Inventory.
This only supports an Inventory created in CSV format; it doesn't
support Apache Parquet or Apache ORC.
"""
s3 = sess.client("s3")
# Download and parse the inventory manifest.
#
# This tells us where the individual inventory files are located,
# and the schema of those files.
#
# See https://docs.aws.amazon.com/AmazonS3/latest/userguide/storage-inventory-location.html#storage-inventory-location-manifest
manifest_obj = s3.get_object(Bucket=bucket, Key=manifest_key)
manifest = json.load(manifest_obj["Body"])
if manifest["fileFormat"] != "CSV":
raise ValueError("This function only supports an S3 Inventory in CSV format")
schema = [s.strip() for s in manifest["fileSchema"].split(",")]
# Go through each of the files in the manifest, and download them
# from S3. Then unpack them and parse them as CSV.
for f in manifest["files"]:
s3_obj = s3.get_object(Bucket=bucket, Key=f["key"])
with gzip.open(s3_obj["Body"], "rt") as infile:
reader = csv.reader(infile)
for row in reader:
# Combine the data in the row with the field names we
# got from the schema in the manifest.
data = dict(zip(schema, row))
# Because the data comes from a CSV, it's all strings.
# Turn it into some slightly nicer types.
data["Size"] = int(data["Size"])
data["IsLatest"] = data["IsLatest"] == "true"
data["IsDeleteMarker"] = data["IsDeleteMarker"] == "true"
data["LastModifiedDate"] = datetime.datetime.strptime(
data["LastModifiedDate"], "%Y-%m-%dT%H:%M:%S.%fZ"
)
# If an object doesn't have a VersionId, we still get
# an empty string in the CSV -- delete the key to mimic
# the behaviour of the ListObjectsV2 API.
if data["VersionId"] == "":
del data["VersionId"]
yield data