Articles




My favourite websites from my bookmark collection
Websites that change randomly, that mirror the real world, or even follow the moon and the sun, plus my all-time favourite website design.
Handling JSON objects with duplicate names in Python
It’s possible, although uncommon, for a JSON object to contain the same name multiple times. Here are some ways to handle that in Python.
A faster way to copy SQLite databases between computers
Dumping a SQLite database to a text file can make it much smaller, which means you can download it faster.
A flash of light in the darkness
If you’re using an image as your background, remember to set a fallback colour as well, especially if you’re in dark mode.
Beyond
None: actionable error messages forkeyring.get_password()I have a wrapper for
get_password()so that if it can’t find a password, you get an error that explains how to set the password, and what password you should choose.Localising the
<time>with JavaScriptI’m using the
<time>element and some JavaScript to display timestamps as human-readable, localised timestamps. Something likeTue, 15 Apr 2025 at 20:45 BSTis easier to read than2025-04-15T19:45:00Z.


Whose code am I running in GitHub Actions?
I wanted to know what third-party code I was using in my GitHub Actions. I was able to use standard text processing tools and shell pipelines to get a quick tally.
Fast and random sampling in SQLite
I tested four approaches, from
ORDER BY RANDOM()to picking randomrowidvalues in Python, and found one that’s both fast and diverse. Here’s what worked (and what didn’t).We all lose when art is anonymised
When art loses its creator, we lose the story behind the image – a plea for attribution in our endless scroll culture.
An unexpected lesson in CSS stacking contexts
While trying to add some simple overlay labels, I stumbled into a sharp edge of a complex CSS feature called “stacking contexts”.
Creating static map images with OpenStreetMap, Web Mercator, and Pillow
I made some simple map visualisations by downloading tiles from OpenStreetMap, then annotating the tiles with Pillow.
Cosmetic updates to this site
I’ve simplified the palette, changed the font, and given several elements a more consistent visual appearance.


Good embedded toots
I replaced Mastodon’s native post embeds with lightweight HTML and CSS snippets that are faster to load, more resilient to outages, and support dark mode – and I had fun doing it.
Making inventory spreadsheets for my LEGO sets
Using the Rebrickable database downloads and sqlite-utils, I can quickly create spreadsheets that let me tick off the parts in each set.
Adding auto-generated cover images to EPUBs downloaded from AO3
I built a handy tool to generate cover images for stories downloaded from AO3, making them easier to browse. Along the way, I learnt about how EPUBs work, the power of static sites, and some gotchas of async JavaScript.
Looking at images in a spreadsheet
The
IMAGEandHYPERLINKfunctions allow me to use a spreadsheet as a lightweight, collaborative space for dealing with images.randline: get a random selection of lines in a file using reservoir sampling
I wrote a tiny Rust tool to get random samples in a memory-efficient way, and I learnt a lot while doing it.
How I test Rust command-line apps with
assert_cmdSome practical examples of how this handy crate lets me write clear, readable tests.
How I use the notes field in my password manager
I use notes as a mini-changelog to track the context and history of my online accounts. I write down why I created accounts, made changes, or chose particular settings.




I deleted all my tweets
I used TweetDeleter to delete about 35,000 tweets, and cut my remaining ties to the site formerly known as Twitter.
Moving my website from Netlify to Caddy
To avoid getting stung by Netlify’s bandwidth charges, I moved this site to a Linux server running Caddy as my web server.
A script to verify my Netlify redirects
I wrote a script that reads my redirect rules, and checks that every redirect takes you to a page that actually exists on my site.
Making alt text more visible
I wrote a JavaScript snippet that shows alt text below all of my images, so I can see when it’s missing, and review it while I’m editing.
Flickr Foundation at iPres 2024
In September, I went to Belgium for a digital preservation conference. I wrote about what I learnt and what I saw for the Flickr.org blog.
Putting history on the map
Antarctic explorers, northern factories, and Hawaiian industry – I wrote about some of the photos I found using the interactive map in the Flickr Commons Explorer.
Two examples of hover styles on images
When I hover over an image, I can add a border to a link, or change the colours of an SVG icon.
Drawing a better bandwidth graph for Netlify
A two-part pie chart lets me see how much bandwidth I’ve used this month, and whether I’m on track to exceed my bandwidth allowance.
Going between Finder and the Terminal
A few shell scripts I use to go between the Finder and the Terminal.








Improving millions of files on Wikimedia Commons with Flickypedia Backfillr Bot
The new bot improves metadata for Flickr photos on Wikimedia Commons, and makes it easier to find out which photos have been copied across.
The surprising utility of a Flickr URL parser
I made a library that knows how to read lots of different forms of Flickr.com URL, and I used
hyperlinkto do it.Documenting my DNS records
Exporting my DNS records as YAML gives me a plaintext file where I can track changes, add comments, and feel more confident about managing my DNS.
Preserving pixels in Paris
I went to France for a conference about archiving the web, and I came back with thoughts and photos.
What comes after AWS?
Whatever displaces public cloud as the default model for large-scale computing has to be more than “AWS, but 3% better”.
What is psephology?
It’s the scientific study of elections and voting, and it comes from the Greek word for “pebble”, because pebbles were used for voting in ancient Greece.
Getting faster Jekyll builds with caching in plugins
I was able to build my Jekyll site much faster by using the built-in caching API.
The Star-Spangled Ballad
If you listen carefully to the Ballad of Willie Watkins, you might hear another song peeking through.
flapi.sh: a tiny command-line tool for exploring the Flickr API
Combining several existing tools to make something that allows for quick experiments and exploration.
The new Flickr Commons Explorer
A new way to browse the photos in the Flickr Commons programme.
Monki Gras 2024: Step… Step… Step…
Swing dancing and prompt engineering are pretty different. But could learning one help us learn the other?
Moving my YouTube Likes from one account to another
Some experimenting with the YouTube API to merge two accounts into one.


The Collected Works of Ian Flemingo
A fledgling author uses a theatre trip to leave the nest. (Or: some props I made for a cosplay event.)
What mammal is that?
In which Apple Photos accidentally tells me about a cool new animal.
Getting the path to the note I have open in Obsidian
Although Obsidian doesn’t support AppleScript, I can use System Events to find out which note I have open.
Setting up Fish to make virtualenv easier
I wrote some shell config to smooth out the experience of using virtual environments in Python.
Making the fish shell more forgetful
A few commands that help me keep unwanted entries out of my shell’s autocomplete.


Finding the biggest items in my Photos Library
A quick script to help move the biggest items out of my main Photos Library.
Spotting spam in our CloudFront logs
Looking for search queries that came from robots, not real people.
Adding locations to my photos from my Apple Watch workouts
My Apple Watch knows where I am, which is handy when I have a camera that doesn’t.
Fare-Wellcome Collection
After nearly seven years, it’s time for something new.
How I set up my Obsidian vaults
The tags, folders, and themes I use to manage information in my Obsidian vaults.
Finding a mystery IAM access key
Using the GetAccessKeyInfo and GetAccessKeyLastUsed APIs can help us trace an IAM key back to its source.
Tag your infrastructure-as-code resources with a link to their definitions
Applying a default tag that points to the IaC definition makes it easy to go from the console to the code.
Parsing CloudFront logs with Python
A couple of functions I use to get access to CloudFront logs as easy-to-use iterators.
My Python snippet for walking a file tree
A function to find all the files in a directory is one of my most-used snippets.
My custom <picture> plugin for Jekyll
How I make images that load quickly and look good for readers, and which are easy for me to manage.
Spy for Spy
A two-handed sapphic romance with a clever narrative twist makes for a compelling and thoughtful new play.
Turning off ECS tasks overnight using an EventBridge Schedule
Calling the UpdateService API on a fixed schedule allows us to turn services off in the evening, and back on again the next morning.
Preserving Dates during JSON serialisation with vanilla JS
How to make sure you get a
Dateback when you callJSON.parseandJSON.stringify.


Have a single definition of “now”
Having one function that you always use to get the current time is super handy when debugging issues that only occur at specific times.
Starting Docker just before I need it
I don’t keep Docker running all the time, but intercepting the
dockercommand means it’s always running when I need it.Snippets to manage albums in Photos.app
AppleScript only allows us to add photos to an album; dipping into Swift and PhotoKit lets us both add and remove photos.
s3tree: viewing a tree of objects in S3 in my terminal
A script to give me a quick overview of some objects in a hierarchical view.
Redecorating my bedroom
Splashing some sunshine in the space where I sleep.
Getting alerts about flaky ECS tasks in Slack
When ECS is “unable to consistently start tasks successfully”, we get a Slack alert that tells us to investigate.
Using templates in Terraform to document a deployment
Terraform can fill in placeholders with exact values from your deployment, for easy copy/paste instructions.
Publishing lots and lots of messages to SNS
Careful use of the
PublishBatchAPI makes it quick and easy for me to send thousands of messages into SNS.Filtering AWS CLI output by tags using jq
Using
from_entriesis a nicer way to deal with the list of Name/Value pairs returned by the AWS CLI.Filtering out bogus requests from Netlify Analytics
Using redirects to filter out bots trying to hack my non-existent PHP installation.
Creating a Python dictionary with multiple, equivalent keys
Using collections.UserDict, we can create a dictionary where dict[key1] and dict[key2] always point to the same value.
Splitting a class into balanced groups
How do you make sure everyone gets to work with everyone else?
Testing JavaScript without a (third-party) framework
The browser can be a pretty good place to run your JavaScript tests.
CSS formatting in the console
Did you know you can use
%cto format yourconsole.logmessages?Going through my old school papers
Digitising and pruning my boxes of paper from school. In which I have nostalgia, sadness, and the sense that everything old is new again.
A Python function to iterate through an S3 Bucket Inventory
Getting something that looks more like the output of the ListObjectsV2 API.
How moving to the cloud took Wellcome’s digital collections to new heights
Building our own platform allowed us to make decisions based on what’s best for the collections, and not the limitations of our digital infrastructure.
A bookmarklet to show which responsive image was chosen
Debugging my <picture> and <source> tags.
Changing the bulb in a Meridian Lighting CIR100B ceiling light
A note to my future self. Also, reverse image search is amazing.
Beware of transparent backgrounds when using AVIF with ImageMagick 6
You probably want to use version 7.


A script to get Live Text from images
Using Apple’s built-in tools to get OCR text from an image, but without going through a GUI.
Getting an Important Internet Checkmark to follow your cursor
Party like it’s 1996! A trailing checkmark cursor will make your Brand Website feel fun and authentic.
How we do bulk analysis of our Prismic content
By downloading all our Prismic documents, we can run validation rules, fix broken links, and find interesting examples.


Redacting sensitive query parameters with koa and koa-logger
Using a custom transporter to modify the log message and remove secret information.
Changing the macOS accent colour without System Preferences
Updating the accent colour everywhere, with immediate effect, using a script written in Swift.
Ten years of blogging
A decade ago, I registered a domain and started writing.
Saving your alt text from Twitter
Twitter’s archives don’t include the alt text you wrote on images, but you can save a copy with their API.
A simple gallery plugin for Obsidian
Making it easier to find all the images in my Obsidian vault.
Agile and iterative project management
Notes from a talk about agile and iterative approaches to project management.
Finding books in nearby library branches
Some web scraping and Python helps me find books that I can borrow immediately.
Some experiments with circle-based art
Casually covering a canvas with coloured circles.




My (tiny) contribution to Rust 1.64
A suggestion for a better error message to help people who work in multiple languages.
Finding redundant data in our Next.js props
A script that helps us optimise our
__NEXT_DATA__, which in turn helps reduce page size.I always want StrictUndefined in Jinja
When I’m writing templates with Jinja, strict behaviour is what I want, even if it’s not the default.
An Egyptian ‘mixtape’ of embroidered material
Repeating geometric patterns make for a colourful and eye-catching piece.
Drawing a circular arc in an SVG
A Python function to help me draw circular arcs, as part of an upcoming project.
How to customise the title of Buildkite builds triggered from GitHub deployments
Getting a more descriptive build label than ‘Deployment’.
Our Place in Space
You don’t realise how big the solar system is until you’ve walked the length of it.
Cut the cutesy errors
If your app has just ruined my day, I need help, not humour.
A surprise smattering of stardom
My last post was surprisingly popular; a few reflections on the experience.


A Martian plaque for a made-up plot
If NASA was the first to land on Mars in For All Mankind, what would the commemorative plaque look like?
One small stitch for yarn, one giant leap for yarn-kind
I made a cross-stitch blueprint of the Apollo Moon lander and the Saturn V rocket.
Fictional phone numbers in For All Mankind
Where did this UK phone number come from?
Creating an Alfred Workflow to open GitHub repos
Automations for my automations.
Experimenting with jq as a tool for filtering JSON
I wanted to learn jq’s more powerful features, so I tried to filter some JSON from the AWS Secrets Manager CLI.
Find the dominant colours in an image in your web browser
Wrapping my CLI tool for finding dominant colours in a lightweight web app.
Running a Rust binary in Glitch
Using different targets to build Rust binaries that will run in Glitch.
Illustrating the cipher wheels of a Lorenz machine
Some old code I wrote to draw cam-accurate illustrations of cipher wheels.
Checking lots of URLs with curl
A bash script to check the HTTP status code of a bunch of URLs, for simple and portable uptime checking.
Beware delays in SQS metric delivery
A mysterious problem with SQS-based autoscaling and an over-eager CloudWatch Alarm.
A tale of two Twitter cards
Some recent changes I’ve made to fix or improve my Twitter cards.
Closing lots of Safari tabs with JXA
To help me keep my tab count down, I wrote a JXA script to close tabs that can easily be recreated.
Why is Amazon Route 53 named that way?
Digging into the history of Route 53, DNS, and port number assignments.
Creating animated GIFs from fruit and veg
Some Python code for turning MRI scans of fruit and veg into animated GIFs.
Creating coloured bookshelf graphics in Rust
Explaining some code that draws coloured rectangles in a way that looks a bit like an upside-down bookshelf.

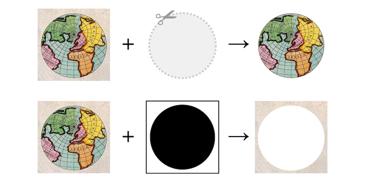
Why is os.sep insufficient for path operations?
Digging into a throwaway comment in the Python documentation.
The ever-improving error messages of Rust
An improvement to Rust’s error handling that I almost reported, until I realised it was fixed.
A tale of two path separators
macOS allows both the slash and colon as path separators, and this caused me no small amount of confusion.
Programatically finding the original filename of a photo in the macOS Photos Library
If you’re looking at a UUID’d file in the PhotosLibrary package, how do you find its original filename?
The Oboe of Optozorax, and Other Objects
A collection of small worldbuilding ideas about magical objects.
Prevent accidentally copying the prompt character in console code snippets
When I include console commands in a blog post, I don’t want somebody to accidentally copy the command prompt. CSS lets me avoid that.
READMEs for Open Science
Slides for a short talk about READMEs, why they’re important, and what they should contain.
Beware of incomplete PDF redactions
If you’re not careful when redacting PDFs, it’s possible to share more information than you intended.
How do you work with non-engineers?
Building a relationship founded on trust and respect.
SeptembRSE: Missing narratives in discussions around diversity and inclusion
An editing toolbar for alexwlchan.net
A bookmarklet that gives me a just-for-me toolbar to make changes to this site.
Getting a monthly cloud costs report in Slack
Sending the AWS bill to Slack, so everyone can be more informed and intentional about spending.
Operations on strings don’t always commute
Is uppercasing then reversing a string the same as reversing and then uppercasing? Of course not.
When is my EventBridge cron expression going to run next?
The AWS console will tell you when your EventBridge rule is going to run… if you know where to look.
Picking perfect planks with Python
How do you pick the right combination of planks to lay a wooden floor? Python and itertools to the rescue!
How to ignore lots of folders in Spotlight
A script that allows me to ignore folders like “target” and “node_modules”, so they don’t appear in search results.
Markdown’s gentle encouragement towards accessible images
The Markdown syntax for images reminds us that we need to write alt text.
Finding misconfigured or dangling CloudWatch Alarms
A Python script that finds CloudWatch Alarms which are based on a now non-existent source.
A few useful GitHub searches
I have hotkeys to search GitHub in several ways, including by user, by repo, and within the work organisation.
Listing deleted secrets in AWS Secrets Manager with boto3 and the AWS CLI
Diving into the internals of the AWS SDK to find deleted secrets.
Visualising how often I write in my journal
A Python script that shows me how often I’ve been journalling, so I can track my progress.
Downloading objects from/uploading files to S3 with progress bars in Python
Making it easier to see how long a file transfer will take, in the terminal.
Drawing coloured squares/text in my terminal with Python
Using AppleScript to detect if a Safari window uses Private Browsing
Finding the app/process that’s using Secure Input
A Python script that shows me the name of processes that have Secure Input enabled.
Building Wellcome Collection’s new unified catalogue search
Collaboration between our digital and collections teams helped to build a single search box for all of our catalogues.

Creating pairs of interlocking rainbow hearts 🌈
A web app for creating pairs of hearts based on Pride flags.
An AppleScript to toggle Voice Control
Making it slightly easier for me to enable and disable Voice Control quickly.
Screaming in the Cloud: Using the Cloud to Preserve the Future
I joined Corey Quinn to discuss my DynamoDB calculator and using the cloud to preserve digital collections.

What year is it? (A tale of ISO week dates)
If you use ICU date formatting, make sure you use the right format specifier for year.
Creating short-lived, temporary roles for experimenting with AWS IAM policy documents
Create short-lived, temporary roles for experimenting with AWS IAM policy documents
“Non-technical users”
A script to copy images from Docker Hub to Amazon ECR
How I read non-fiction books
I take notes so I remember more of what I read.
Maths is about facing ambiguity, not avoiding it
School tells us that “Maths always has one right answer!”, which is a convenient but unhelpful lie.
Remembering if a <details> element was opened
A JavaScript function that remembers if a details element was reopened, and keeps it open when you reload the page.
A Python function to ignore a path with .git/info/exclude
If your Python script creates a file that you don’t want to track in Git, here’s how you can ignore it.
How do I use my iPhone cameras?
A script to work out which camera I use most often on my iPhone, and whether I’d miss a telephoto lens.
The danger of bad error messages
An Excel mistake shows why learning to write good error messages is a critical skill for software developers.
A new README for docstore, my tool for organising scanned paperwork
Although I don’t expect anyone to use it directly, there might be some interesting ideas that could apply elsewhere.
Replicating Wellcome Collection’s digital archive to Azure Blob Storage
How and why we keep copies of Wellcome’s digital collections in multiple cloud storage providers.
Using qlmanage to create thumbnails on macOS
How you can invoke Quick Look on the command-line to generate high-quality thumbnails.
Two Python functions for getting CloudTrail events
S3 prefixes are not directories
Although an S3 prefix looks a lot like a directory path, they aren’t the same. Whether or not you include a trailing slash can change the behaviour.
S3 keys are not file paths
Although an S3 key looks a lot like a file path, they aren’t always the same, and the distinction can trip you up.
Using fuzzy string matching to find duplicate tags
Getting a Markdown link to a window in Safari
Why do programming languages have a main() function?
Lots of programming languages have a function called main() where code starts executing. Where does this come from?
Running concurrent Try functions in Scala
If you have a function that returns Try[_], how do you call it more than once at the same time?
What does \d match in a regex?
It’s more complicated than I thought.
How to do parallel downloads with youtube-dl
Changing the accent colour of ICNS icons
Playing with macOS ICNS image files to create colourful new icons.
Using AppleScript to open a URL in Private Browsing in Safari
Fat shaming in The Good Place
How many good person points do you lose for making a joke about somebody’s weight?
Archive monocultures considered harmful
We are better off when the same topic is represented in multiple, different archives.
Finding the months between two dates in Python
Getting every item from a DynamoDB table with Python
A Python function that generates every item in a DynamoDB table.
Showing human-friendly dates in JavaScript
What’s a nicer way to show a date than an ISO 8601 timestamp?
The Sachsenhausen concentration camp
Feeling the weight of death in a former concentration camp.
Moving messages between SQS queues
You can send messages to a DLQ if they fail processing. What if you fix the bug, and you want to resend the failed messages?
Downloading the AO3 fics that I’ve saved in Pinboard
A script that downloads the nicely formatted AO3 downloads for everything I’ve saved in Pinboard.
Social media as a growth culture for opinions
Using social media can lead us to have more opinions than we really need. Can we fix that?
Taking tuple unpacking to terrible places
I want to assign a bunch of variables to True, but I don’t know how many there are. Reflection to the rescue!
Make it safe to admit mistakes
You can’t stop people making mistakes, but you can make it more likely that they’ll admit their next mistake to you.



Give your audience time to react
Rehearsing a presentation only tells you the minimum length of time you’ll take. If you’re speaking to a time limit, remember to leave some slack.
Exploring an unknown SQL server
You’re handed a SQL server which has some data, but you don’t know anything about the schema. What do you do?
Thinking about your gender
Cis people are allowed to think about their gender too.
Complex systems have complex failures
When a complex system fails, it’s usually a combination of problems, not a single person’s mistake.
Comparing JSON strings when testing in Scala
There are lots of ways to format JSON. How do you know if two JSON strings have the same data, just differently formatted?
Adventures in euphoria and embodiment
We all have bodies, and I’ve been trying to become more self-aware and connected with mine.
Access to information is a privilege
A snippet for downloading files with Python
Storing language vocabulary as a graph
Experimenting with a way to store words and phrases that highlights the connections between them.
Inclusion can’t be an afterthought
Notes from a talk about inclusion in design and unconscious bias.
Rich enough to make bad choices
If you’re rich, not only can you invest in good boots, you can also invest in experimental boot-making startups.
Sick leave while working from home
It’s okay to take sick leave if you’re working from home.
Creating striped flag wallpapers with Pillow
A Jekyll filter for adding non-breaking spaces
A way to avoid awkward line breaks in the middle of phrases.
Adjusting the dominant colour of an image
Adjusting the hue to get different colour variants of the same image.
Storing multiple, human-readable versions of BagIt bags
How we use the fetch.txt file in a bag to track multiple copies of an object in our digital archive.
A deletion canary: testing your S3 bucket permissions
If you’ve tried to disable deletions in your S3 buckets, how do you know they’re working?
An interactive map of British railway stations 🚂
A map I use to plot which railway stations I’ve visited.
Generating pride-themed Norse valknuts with Python 🌈
A web app to generate mashups of Norse valknuts and Pride flags.
Finding the CPU and memory bottlenecks in an ECS cluster
This YAML file will self-destruct in five seconds!
YAML allows you to execute arbitrary code in a parser, even if you really really shouldn’t.
Some useful spreadsheet functions: FORMULATEXT, MATCH, CONCATENATE and INDIRECT
November 2019 scripts: downloading podcasts, retrying flaky errors, Azure and AWS
How I scan and organise my paperwork
My procedure for scanning paper, and organising the scanned PDFs with keyword tagging.
Saving a copy of a tweet by typing ;twurl
An AWS costs graph that works for me
How I get a Cost Explorer graph for the last 30 days of spending, broken down by service.
Digital preservation at Wellcome Collection
Slides from a presentation about our processes, practices, and tools.


Sans I/O programming: what, why and how (PyCon UK talk)
Code that pushes I/O to the boundary is simpler, easier to reuse and easier to test.
Adding religious holidays to my calendar
The rough edges of filecmp
The filecmp module has a confusing API, and it just caught me out.
Experiment: GitHub code search with de-duplication
Drawing with triangular coordinates in SVG
Some code and trigonometry for drawing shapes that don’t fit neatly into a rectangular grid.
Streaming large objects from S3 with ranged GET requests
Reliably reading a large object by stitching together multiple GetObject requests into a single Java InputStream.
Iterating over the entries of a compressed archive (tar.gz) in Scala
Code to turn an InputStream into an Iterator of entries from a tar.gz file or similar compressed archive in Java/Scala.
Finding divisors of a number with Python
Using unique prime factorisations and itertools to find all the divisors of a number.
Creating preview thumbnails of PDF documents
Listing even more keys in an S3 bucket with Python
Python functions for getting a list of keys and objects in an S3 bucket.
Ten braille facts / ⠼⠁⠚⠀⠃⠗⠁⠊⠇⠇⠑⠀⠋⠁⠉⠞⠎
Where does braille come from? How was braille originally written? What can you write in braille today? And more.
An inescapable conclusion
After months of introspection and soul-searching, I’ve had some big realisations about my identity.
A Jekyll filter for obfuscating email addresses
The original Markdown implementation would do randomised hex/decimal encoding to help obscure email addresses, and I do the same in Jekyll.
Reading a Chinese dictionary / 读一本中文字典
Although paper dictionaries are mostly a thing of the past, knowing how to use a Chinese dictionary helps me learn the rest of the language.
Converting Acorn images on the command-line
I wrote some AppleScript to help me do batch conversion of Acorn images into formats like PNG and JPEG.
Hey Apple, cycle tracking isn’t just for women
At WWDC, I was disappointed to see Apple pitch period tracking exclusively towards women, and not in a more gender-inclusive way.
A script for getting cover images from mobi ebooks
Questions to ask when writing a trans inclusion policy
Notes on common themes and ideas in a variety of trans inclusion policies, as we start thinking about writing a policy at Wellcome.
Falsehoods programmers believe about Unix time
It’s not quite the number of seconds since 1 January 1970.
Creating a locking service in a Scala type class
Breaking down some tricky code that allows us to lock over concurrent operations.
Reversing a t.co URL to the original tweet
Twitter uses t.co to shorten links in tweets, so I wrote some Python to take a t.co URL and find the original tweet.
Some tips for conferences
Getting a transcript of a talk from YouTube
Using the auto-generated captions from a YouTube video as a starting point for a complete transcript.
Creating a GitHub Action to auto-merge pull requests
Saving myself the trouble of clicking that pesky “merge” button.


Finding the latest screenshot in macOS Mojave
Atomic, cross-filesystem moves in Python
Explaining some code for moving files around in a way that’s atomic and works across filesystem boundaries.
Checking Jekyll sites with HTMLProofer
Working with really large objects in S3
Code for processing large objects in S3 without downloading the whole thing first, using file-like objects in Python.
Monki Gras 2019: The Curb Cut Effect
Slides and notes for my talk ‘The Curb Cut Effect’. Making something better for disabled people can make it better for everybody.
Notes from You Got This 2019
Notes from the inaugural ‘You Got This’ conference, a conference about creating a healthy and sustainable work life.
Notes on reading a UTF-8 encoded CSV in Python
Some notes on trying to do this in a way that supports both Python 2 and 3, and the frustration of doing so.
Iterating in fixed-size chunks in Python
A snippet for iterating over an arbitrary iterable in chunks, and returning a smaller chunk if the boundaries don’t line up.
Getting credentials for an assumed IAM Role
A script that creates temporary credentials for an assumed IAM role, and stores them in ~/.aws/credentials.
A script for backing up Tumblr posts and likes
Since Tumblr users are going on a mass deletion spree (helped by the Tumblr staff), some scripts to save content before it’s too late.
Keeping track of my book recommendations
The three lists I use to manage my book recommendations.
My visit to the Aberdulais Falls
Pictures from my trip to the waterfalls and former tin plating works at Aberdulais.
Finding SNS topics without any subscriptions
I’m trying out Go, and I wrote a tool to help me find SNS topics that don’t have any subscriptions.
Peering through MRI scans of fruit and veg
What do you see when you pass fruit and vegetables through an MRI scanner? And how many animated GIFs can you make?
Custom 404 responses in Finatra
A snippet for returning a custom 404 response in a Finatra app when somebody requests a missing page.
Assume worst intent (designing against the abusive ex)
How do we design services and platforms to reduce the risk of harassment and abuse from other users?
Building trust in an age of suspicious minds
Notes and slides from my PyCon UK 2018 keynote. In a world where people are less and less trusting, how can we take steps to make ourselves more trustable?
Signs of the time
A few lessons I learned while doing the signage for this year’s PyCon UK.
A basic error logger for Python Lambdas
A snippet to make it a bit easier to debug errors in AWS Lambda functions written in Python.
Making the venue maps for PyCon UK
A quick braindump of my thoughts from drawing some venue maps for PyCon UK.
Implementing parallel scan in DynamoDB with Scanamo
Prototype code for running a parallel scan against a DynamoDB table, and using Scanamo to serialise rows as Scala case classes.
Avoiding the automatic redirect on Tumblr posts
I see an intermittent 303 Redirect when trying to navigate to a Tumblr ‘permalink’; changing the User-Agent seems to fix it.
Ideas for inclusive conferences and events
A collection of ideas and suggestions for running conferences which are more inclusive and accessible. Based on my experiences at AlterConf, PyCon UK, and similar events.
Moving my calendars from iCloud to FastMail
I recently discovered that iCloud was deleting my old calendar entries, so I switched to FastMail.
A robot leaked my SSH keys
A cautionary tale of a daft incident where I leaked a set of SSH keys to GitHub.
My favourite iMac accessory
Adding a USB extension cable to my iMac makes a world of difference.
Drawing ASCII bar charts
A Python snippets for drawing bar charts in command-line applications.
Creating a data store from S3 and DynamoDB
A new storage layer for large records in the Catalogue pipeline.
Beware of logged errors from subprocess
If you use Python’s subprocess module, be careful you don’t leak sensitive information in your error logs.
Two shortcuts for using S3 in the shell
Two shell functions for editing and inspecting S3 objects as if they were local files.
(Anti) Social Media
Slides and notes for a talk about online harassment, and why you should always design with an abusive ex in mind.
Notes on A Plumber’s Guide to Git
Git is a fundamental part of many modern developer workflows – but how does it really work under the hood? In this workshop, we’ll learn about the internals of Git.
The Hypothesis continuous release process
How we do continuous releases of hypothesis-python, and why.
Keep an overnight bag in the office
Although hopefully never needed, I think it’s worth keeping an overnight bag in your workplace.
Getting helpful CloudWatch alarms in Slack
How we use AWS Lambda to send messages about our CloudWatch alarms to Slack, and some ways we add context and information to make those messages as helpful as possible.
Getting every message in an SQS queue
Code for saving every message from an SQS queue, and then saving the messages to a file, or resending them to another queue.
Listing keys in an S3 bucket with Python, redux
Python functions for getting a list of keys and objects in an S3 bucket.
IP and DNS addresses for documentation
If you’re writing technical docs and need placeholder IP addresses or DNS hostnames, there are some special values just for you!
Using Loris for IIIF at Wellcome
How we use Loris to provide a IIIF Image API for browsing our collections at Wellcome–how it runs in AWS, store our high-resolution images, and monitor the service.
Your repo should be easy to build, and how
Making your repo easy to clone and build is very important. This post explains why, and how I’m using Make and Docker to achieve that goal.
Pruning old Git branches
Two commands for managing Git branches: one for deleting branches which have already been merged, one for deleting branches which were deleted on a remote.
Downloading logs from Amazon CloudWatch
A detailed breakdown of how I wrote a Python script to download logs from CloudWatch.
My favourite WITCH story
As the WITCH computer celebrates five years since its reboot at TNMoC, a fun story of how it was left to run at Christmas.
Don’t tap the mic, and other tips for speakers
Tapping the microphone to test it can be bad for all sorts of reasons – and other advice from the Nine Worlds speaker guidelines.
A plumber’s guide to Git
How does Git work under the hood? How does it store information, and what’s really behind a branch?
Using privilege to improve inclusion
In the tech industry, how can we be more aware of our privilege, and use that to build inclusive cultures?
Lightning talks
Why I like the lottery system used to select lightning talks at PyCon UK this year.
Displaying tweets in Keynote
Slides for showing tweets that look like tweets on slides in Keynote and PowerPoint.
Using hooks for custom behaviour in requests
I often have code I want to run against every HTTP response (logging, error checking) — event hooks give me a nice way to do that without repetition.
Using pip-tools to manage my Python dependencies
How I use pip-tools to ensure my Python dependencies are pinned, precise, and as minimal as possible.
Some useful Git commands for CI
A couple of Git commands that I find useful in builds and CI.
Ode to docopt
Why I love docopt as a tool for writing clean, simple command-line interfaces.
A Python module for lazy reading of file objects
I wrote a small Python module for lazy file reading, ideal for efficient batch processing.
Backing up full-page archives from Pinboard
A Rust utility for saving local copies of my full-page archives from Pinboard.
Backing up content from SoundCloud
Listing keys in an S3 bucket with Python
A short Python function for getting a list of keys in an S3 bucket.
Accessibility at AlterConf
For accessibility and inclusion, AlterConf sets a high bar to beat.
A Python interface to AO3
AO3 doesn’t have an official API for scraping data - but with a bit of Python, it might not be necessary.
Experiments with AO3 and Python
AO3 doesn’t have an official API for scraping data - but with a bit of Python, it might not be necessary.
Another example of why strings are terrible
Pop quiz: if I lowercase a string, does it still have the same length as the original string?
Some low-tech ways to get more ideas
A few suggestions for “low tech devices” that aid in the process of generating ideas.
Use keyring to store your credentials
If you need to store passwords in a Python application, use the keyring module to keep them safe.
Creating low contrast wallpapers with Pillow
Take a regular tiling of the plane, apply a random colouring, and voila: a unique wallpaper, courtesy of the Python Imaging Library.
Tiling the plane with Pillow
Using the Python Imaging Library to draw regular tilings of squares, triangles and hexagons.
Why I use py.test
Why py.test is my unit test framework of choice in Python.
A shell alias for tallying data
A way to count records on the command-line.
My travelling tech bag
aspell, a command-line spell checker
Silence is golden
PyCon had a dedicated quiet room for people to get some downtime, and I think it’s a great idea.
Live captioning at conferences
Live captioning of conference talks was an unexpected bonus at this year’s PyCon UK.
Python snippets: Cleaning up empty/nearly empty directories
A pair of Python scripts I’ve been using to clean up my mess of directories.
Python snippets: Chasing redirects and URL shorteners
A quick Python function to follow a redirect to its eventual conclusion.
Clearing disk space on OS X
A few tools and utilities I’ve been using to help clear disk space on my Mac.
Reading web pages on my Kindle
A Python script I wrote that let me sends web pages from my Mac and my iPhone to my Kindle.
Introduction to property-based testing
Testing with randomly generated examples can be a good way to uncover bugs in your code.
Finding 404s and broken pages in my Apache logs
A Python script for finding 404 errors in my Apache web logs - and by extension, broken pages.
A Python smtplib wrapper for Fastmail
A quick python-smtplib wrapper for sending emails through Fastmail.
Safely deleting a file called ‘-rf *’
If for some reason you create a file called
-rf *, it’s possible to delete it safely. But really, don’t create it in the first place.Treat regular expressions as code, not magic
Regexes have a reputation for being unreadable monsters, but it doesn’t have to be that way.
Get images from the iTunes/App/Mac App Stores with Alfred
Using Alfred and a Python script to retrieve artwork from the iTunes, App and Mac App Stores.
Exclusively create a file in Python 3
If you want to create a file, but only if it doesn’t already exist, Python 3 has a helpful new file mode
x.How I use TextExpander to curb my language
I have some TextExpander snippets that I use to cut out words I don’t want to write.
The Skeletor clip loop, 2015 edition
Updating the Skeletor clip loop chart for the 2015 Clip Show.
Pretty printing JSON and XML in the shell
Backups and Docker
The Docker folder on your computer can quickly fill up space. Don’t forget to exclude it from backups.
Export a list of URLs from Safari Reading List
A Python script for getting a list of URLs from Safari Reading List.
Python and the BBC micro:bit
Playing with a tiny computer that runs Python.
Quick shell access for Docker containers
A Bash function for quickly getting shell access to Docker containers.
Review: Effective Python
A review of Effective Python, by Brett Slatkin.
Finding even more untagged posts on Tumblr
A new version of my site for finding untagged Tumblr posts.
Useful Bash features: exit traps
Persistent IPython notebooks in Windows
Configuring an IPython notebook server that is always running and easily accessible in Windows.
Safer file copying in Python
A Python script for non-destructive file copying/moving.
Useful Git features: a per-clone exclude file (.git/info/exclude)
Another way to ignore untracked files in Git.
Cloning GitHub’s Contributions chart
I made a clone of GitHub’s Contributions graph to use as a motivational tool.
Some exam advice
Some advice for students sitting technical exams
Pygmentizr
A web app for applying syntax highlighting to code using the Pygments library.
Tidying up my 1Password
Adding checkboxes to lists
A bookmarklet to add checkboxes to lists in the browser.
Kitchen sink security
Acronyms
Skeletors All the Way Down
Unpacking sets and ranges from a single string
Notes on Tumblr
Playing with 404 pages
My new standing desk
A standing desk that I built solely from IKEA parts.
Updates to my site for finding untagged Tumblr posts
A TextExpander snippet for Amazon affiliate links
A quick Alfred workflow for opening recent screenshots
Thoughts on Overcast
Some thoughts on Marco Arment’s new podcast player, Overcast.
Getting plaintext LaTeK from Wolfram Alpha
Skeletor!
Finding untagged posts on Tumblr, redux
Finding untagged posts on Tumblr
Automatic Pinboard backups
A script for automatically backing up bookmarks from Pinboard
Darwin, pancakes and birthdays
Looking at whether Darwin ever missed out on birthday cake for pancakes
Zero
An essay about the number zero that I wrote for school.